
Building Multi-Agent Systems (Part 2)
Updated methods for scaling LLM-based agents to handle complex problems reliably.

My now 6-month-old post, Building Multi-Agent Systems (Part 1), has aged surprisingly well. The core idea, that complex agentic problems are best solved by decomposing them into sub-agents that work together, is now a standard approach. You can see this thinking in action in posts like Anthropic’s recent deep-dive on their multi-agent research system.
But while the "what" has held up, the "how" is evolving faster than expected. The playbook of carefully orchestrating agents through rigid, instructional workflows is already becoming outdated. As foundation models get dramatically better at reasoning, the core challenge is no longer about designing the perfect workflow; it’s about engineering the perfect context. The relationship has inverted: we don't just give instructions anymore; we provide a goal and trust the model to find its own path.
In this post, I wanted to provide an update on the agentic designs I’ve seen (from digging in system prompts, using AI products, and talking to other folks in SF) and how things have changed already in the past few months.

What’s the same and what’s changed?
We’ve seen a lot more AI startups, products, and models come out since I wrote the last post and with these we’ve seen a mix of new and reinforced existing trends.
What has stayed the same:
Tool-use LLM-based Agents — We are still fundamentally leveraging LLMs as the foundation for agents and using “tool-use” (aka LLM generates magic text to call an external function which is run programmatically and injected into the context).
Multi-agent systems for taming complexity — As with all software systems, features get added and systems get complex. With agents fundamentally getting worse with complexity, introducing carefully architected subagents to modularize the system is an overwhelmingly common trend.
Tools are not just APIs but agent-facing interfaces — Contrary to what a lot of official MCP implementations look like, agent-facing tools to work reliably are best crafted around the limitations of the LLM. While you could just mirror tools around your REST API, you’ll have better luck designing them around your user-facing frontend (making them intuitive, simpler, etc.).
Computer Use still isn’t great — One of the most obvious ways task automation agents could manifest is by just doing the exact same things humans do for the same task on a computer (i.e. clicking, typing, looking at a screen). While models have gotten much better at this, as of this post, nearly every “operator”-type product has been either unreliable for simple tasks or limited to a narrow subset of computer tasks (e.g., operating within a special browser).
What is different:
Reasoning models with tool-use are getting good — Foundation model providers (OpenAI, Anthropic, etc) have finally set their optimization objectives on making good tool-calling agents and you’ve seen a dramatic improvement across agentic benchmarks like Tau-Bench and other multi-step SWE tasks. Unlike models 6 months ago, recent models have gotten significantly better at handling tool failures, self-debugging, environment exploration, and post-tool result planning (e.g. previously they would often overfit to their initial plan vs changing based on environment observations).
Agents can go longer without getting stuck — Multi-agent architectures, better reasoning, and longer actually-useful context windows have meant that applications have been able to extend how long agents can run without human intervention. This has translated into new UXs for long running agents, an increase in the scale of tasks they can perform, and product that applications can get away with charging a lot more tokens for.
More intelligence, means less architecture-based orchestration — As expected from the part 1 post, better models have meant less of a need to carefully craft an agent architecture around complexity. This has also led to a shift in goal and context-based prompting for these agents rather than what I would call “instructional” or “workflow”-based prompts for agents. You trust that if you engineer your context right1 and give the agent a clear goal, it will optimally come to the right answer.
As models improve, we are shifting from providing instructions to just providing context and goals. You trust that if you provide the right context and a clear goal, the agent will find the optimal path, even if it's one you didn't design. As an interesting example of this, at work, we have a Sonnet-based Slack bot with a simple system prompt:
You are the GenAI team slack channel helper.
If the user asks a question about a feature or how things work:
ONLY use the confluence pages below to answer questions
DO NOT provide ambiguous answers, only respond if documented
< confluence pages >
And one day I saw that it was answering some questions and providing advice/workarounds that were undocumented and immediately assumed it was some nasty high-confidence hallucination. Replaying the request with our debug tool, showed that Sonnet just decided that answering the user’s question was more important than “ONLY use the confluence pages”, then using just github_search(query: str) it found our team’s part of the monorepo and the specific feature being asked about, looked at the code for how the logic works and how requests could be modified to workaround a limitation, and then translated that back into an answer for the user. Not only was it impressive that Sonnet got the correct answer, it was interesting (and somewhat spooky) that it just ignored the “workflow” we specified for how to answer questions to achieve the higher level goal here or accurately answer the help channel’s questions.
Updated Multi-Agent Architectures
In the last post, I proposed three multi-agent primitives: the assembly line, the call center, and the manager-worker pattern. The recent trends point to more and more applications going for manager-worker (aka what Anthropic calls “orchestrator-worker”) which makes a lot of sense given the “what’s different” above. The models are getting good enough to do their own planning, performing long-running agentic loops2, and are starting to feel bottlenecked by the architects ability to tell it how it should be solving problems.
Here are three updated architectures for today’s models based on what I’ve seen and experimented with. These are not mutually exclusive, and it should be easy to see how you could combine them to build your application.
Lead-Specialist Agents

The “lead-specialist” architecture puts a driver agent in charge of planning and orchestrating how a task is solved while delegating to specialists that manage complexity and the context within their own agentic loops. I’m not calling this manager-worker or orchestrator-worker, as this is more of a subclass where the worker is specifically responsible for a domain-specific subtask.
This pattern works great when you are able to modularize complexity into these independent specialists (which might correlate with products, datasets, or groups of similar tools). This is especially handy when you have a ton of tools (>30) and related how-to-use instructions that a single agent struggles to reliably follow.
Failures occur when specialists have cross-dependencies that the lead fails to provide (e.g. car rental specialist makes an faulty assumption about a decision made by the flight specialist in a travel app).
Examples
An advanced travel assistant. The user input is passed into a lead who asks experts (via tool-use) subdomain-specific questions. The expert responses are then compiled by the lead into the final answer.
[user prompt] →
Travel Lead
Flights Specialist
Hotels Specialist
Car Rental Specialist
Weather Specialist
→ [recommendations, bookings]
Anthropic’s multi-agent research product.
Master-Clone Agents
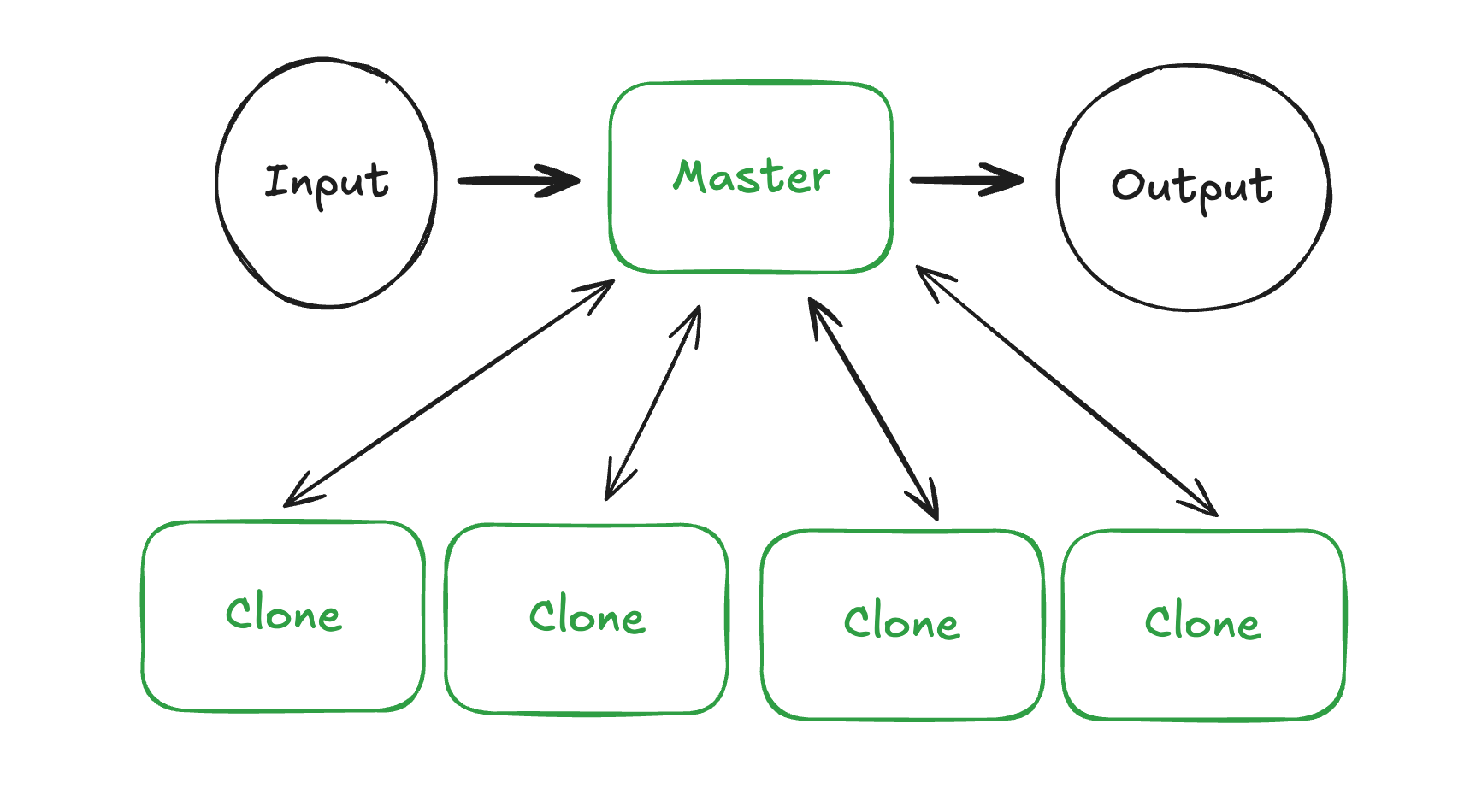
The “master-clone” architecture features a single agent that spins off copies of itself to solve the problem. The master agent keeps its own focus high-level, while the clones tackle specific, delegated subtasks using the same tools and context as the main agent. While it looks similar to the architecture above, the critical difference is that all subagents have mostly identical application context and tools (with clones having an additional master-provided task description).
This pattern works great for long highly multistep tasks where you want the agent to have even more control on how it delegates subproblems to versions of itself. While adding complexity to the master prompt, it reduces the runtime complexity of the agent as even cross-subdomain tasks can be delegated to clones.
Failures occur when the application complexity means every agent requires a ton of context in all domains to function correctly (i.e. agent will start to miss things and it will be costly).
Examples
An advanced travel assistant. The user input is passed into the master who asks copies (via tool-use) subtask questions. The expert responses are then compiled by the master into the final answer.
[user prompt] →
Travel Master
Travel Clone “find weather and high level travel recommendations“
Travel Clone “find potential flight, hotel, car options based on <recommendations>“
Travel Clone “book everything in this <itinerary>“
→ [recommendations, bookings]
Anthropic’s Claude Code.
Scripting Agents

The “scripting” architecture, is effectively “Claude Code is your agent architecture”. Even if you are building a non-code related application, you structure your problem as a scripting one by providing the agent raw data and APIs over handcrafted MCPs or tools. This has the bonus of being in some sense architecture-free while leveraging all the magic RL Anthropic used to make Sonnet good within a Claude Code like scaffolding. While this pattern might feel a bit silly for non-data analysis tasks, the more I work with Sonnet, the more this doesn’t feel that crazy.
This pattern is great when traditional tool-use is highly inefficient or becomes a bottleneck (i.e. it’s magnitudes faster for the agent to write a python script to analyze the data over it’s existing tools). It’s also handy when you have complex agent created artifacts like slides, charts, or datasets.
Failures occur due to the complexity of managing such a sandbox environment and when an application’s task doesn’t cleanly lend itself to a scripting parallel.
Examples
An advanced travel assistant. The user input is passed into the scripter who uses code to solve the problem. The scripter runs and iterates on the scripts, using their results to arrive at a final answer.
[user prompt] →
Travel Scripter
Env: Linux, python3.11, weather API, flights.csv, hotels.csv, cars.csv
Write, run, and iterate on “custom_travel_solver.py”
→ [recommendations, bookings]
Open-Questions
Answered questions from part 1:
How much will this cost? A lot of $$$! But often, when designed well, comes with a wider set of problems that can be solved or automated making thousand dollar a month agent subscriptions actually not that crazy.
What are the actual tools and frameworks for building these? I still use custom frameworks for agent management while I see many using CrewAI, LangGraph, etc which is also reasonable. I think given the trend of letting the intelligence of the model doing most of the orchestration, I expect rolling your own basic agentic loop is going to get you pretty far (RIP a few startups).
How important is building a GenAI engineering team modeled around a multi-agent architecture? This seems to be working well for me and other larger organization’s building agents. Breaking your problem down into multiple independent agent parts does indeed lend itself parallelism across human engineers. That being said, most prompt updates and tool schema tweaks I’m making now are happening through Claude (as my assistant Sr. Prompt Engineer given some eval feedback)3.
Some new questions I’ve been thinking about:
How comfortable are we not being in control of how agents work towards a goal? How does this change when they are making important decisions? The paperclip maximizer is becoming a little too real while it’s clear that the more effective agentic systems will be the ones that manage their own planning and workflows. Claude especially will already ignore system instructions to achieve what it believes as a higher level goal4 and I guess that’s awesome for the efficacy of a support bot with limited system access, but as agents become more monolithic and “powerful” we are putting a lot of trust into models to do the right thing (for human security, privacy, and safety).
What’s the right UI/UX for long running agentic tasks? The chat UI works OK for quick answers but not so much for long-running or async tasks. Recent “deep research” products have had interesting solutions to this but it will be interesting to see how products provide users with the right observability for agents running over the course of hours to days (especially when they are being charged usage-based pricing!).
“Context engineering” is a recent buzzword that’s come up for this. As the agents get better at planning and solving, your bottleneck becomes how to structure context (literally the text provided to the LLM as input as prompts or via tools) to make it reliable and maximally effective.
For those unfamiliar with what I’m calling the “agentic loop”, it’s basically the code you see in nearly every agent application that (1) calls the LLM, (2) did it want to use a tool or did it come to an answer, (3) if tool, run tool programmatically, and append result, go to 1, (4) if answer, end. You can see a literal example in the Anthropic cookbook.
Anthropic also touches on this in their multi-agent article, “Let agents improve themselves. We found that the Claude 4 models can be excellent prompt engineers. When given a prompt and a failure mode, they are able to diagnose why the agent is failing and suggest improvements. We even created a tool-testing agent—when given a flawed MCP tool, it attempts to use the tool and then rewrites the tool description to avoid failures.”
I’ll note that spooky articles like How LLMs could be insider threats are often portrayed (imho) in a way to exaggerate the capabilities and dangerous motives of the models. It’s like giving an LLM a contrived trolly problem and then depending on what happens the headline is either “AI chooses to kill someone” or “AI chooses to kill 5 people”. But high level yeah, these models have the potential to do some crazy stuff when you give them tools to interact with the outside world.