
How I use AI (2025)
Some thoughts on using AI for everyday things.

My strategy for navigating the AI wave rests on a single, core assumption: AI will, before I retire, do everything I do for an income. Sure, we’ve seen companies hire back human workers, AI startups exposed as low-paid human workers, and vibe-coded security incidents, but to me, these are a bit of a distraction from just how much AI has changed things and how far they still have to go.
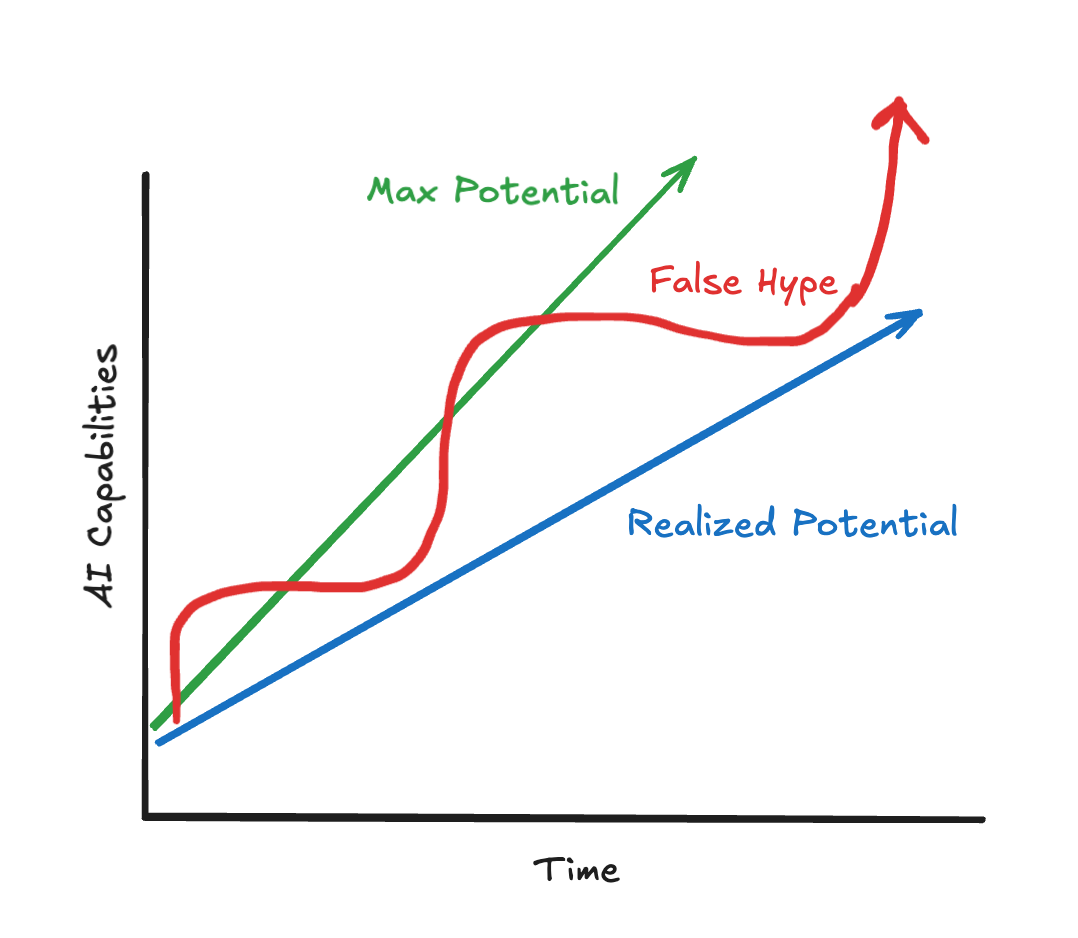
While the Overton window has definitely shifted towards "AI-is-useful" over time, it’s still surprisingly common how wide-ranging opinions are on it (anecdotal SF metric: ~20% still think the SWE role will be done mostly manually). Even now, the majority of adults (81%) hardly use any AI as part of their jobs. I continue to assume it’s because the world (opinions, applications, processes, policies) moves much slower than the technical progress we’ve seen with LLMs.
In this post, I wanted to snapshot how I’ve learned to use it, how much I spend, and the wider impacts on heavy AI dependence. I’ll try to focus on the general non-engineering aspects, but you may also be interested in Working with Systems Smarter Than You and AI-powered Software Engineering.
What I just don't do anymore
I’ll start with what, for the most part, I just don’t really do anymore. This isn’t a list of ways I’m saying you should be using AI—do what works for you—but is more of a reflection on how things have changed for me over the last few years.
Writing code — In my past posts, I gave rough estimates of 15% (Oct 2024) and 70% (March 2025). This is now 100%, as in for all recent PRs (monorepo, not just unit-tests or greenfield projects) no human code was written outside of the Cursor chat window. It’s a bit of a weird feeling to always be in reviewer-mode now but it’s also pretty cool to have such a higher level of parallelism getting things done1. I was way off when I predicted it wouldn’t be till 2028+.
Search and research — Maybe a more obvious one but I’ve finally gotten away from the Google Search reflex and not just as a specific application but in the way I ask questions and absorb content. There’s a mix of quick questions (“what does xyz mean?”), but more and more, my scope of queries isn’t about specific facts but wider decisions given lots of context (which I’ll discuss more in a later section). A trivial case would be targeted searches for preferred restaurants in my area would now just be a “<personal context>, what should I eat?“. Notably, most of the content I read and things I learn is from a chat-window with brief source skims for verification.
Asking advice-related questions — I say this without really taking a side yet on whether this is a more good or bad thing but pretty much most questions I would have originally asked a mentor, manager, or senior domain expert are now mostly solvable by providing the right context to an LLM and often source documents written by those experts. Questions like, “given this situation, what do you think I should do?”; “here’s approach A, B — I’m leaning A, but what could go wrong?”; “for this purchase, what are the key things I should look for?”; or “what itinerary do you recommend, given where I am and what I like?”. There’s definitely an art here to avoid a lot of the ways AI answers can mislead you (I’ll discuss more).
Making decisions with AI
I’m a strong believer in the idea of Decision Fatigue—the idea that the sheer number of complex decisions we make in a day is a large contributor to how tired we are. While I have certain strong preferences and values, there are a lot of decisions that I don’t really want to continuously make (ranging from how to respond to a specific slack message to what specifically I should order for lunch). In a more math-y way, I have N values that need to be applied to K situations — that’s O(N * K) mental compute and fatigue that I’d rather give to an AI.
There are a few strategies I use to make this more effective:
Providing a lot of context — It’s still pretty common to see people using ChatGPT and relying on built-in memory to answer open-ended questions. Additionally, most people heavily underestimate the scope of context that’s useful for a given decision. “Plan a trip to NYC” will result in something that takes a decent amount of time to review and iterate on — instead “Plan a trip to NYC. <travel budget/preferences for everyone in the group>, <exact dates>, <how I like things formatted>, …” might one-shot what you need. The UX is still a bit clunky but I keep docs just for copy-pasting large amount of preferences into the chat window along with my, often brief, question. Specifically, I keep a 3-page context for personal for life decisions2 and around 10 to 400-pages of context for making decisions at work. I find there are a ton of situations where context I didn’t think was relevant ended up as part of the reasoning for a specific decision (in a useful, very witty way).
Handling a lack of context — There may be cases where I don’t have the context to provide for making a decision (e.g. private, not easily copy-paste-able, or I truly don’t know). For these you can leverage hypotheticals to tease out how that decision would vary depending on this unprovided context. Examples: “How might this decision change based on values?” (unknown values), “What are potential root causes for the situation and how does that change the mitigation?” (unknown root cause), “What mistakes am I likely to make and what could I do to prevent them” (unknown mistakes).
Avoiding AI agreeableness — If you ask “why is A the best decision over B”, it will often tell you exactly why that is regardless of which option is actually better in the context. An immediate solution is to reframe the question as, “<context>, A or B?” but even this isn’t foolproof, as how you word A, B, and the context itself can lead the assistant with a less detectable bias. Some fancier strategies include having two separate assistants debate the topic (forcing each to take a different side) or using again hypotheticals, “what small changes to <context> could change this decision?”. You can then read these over to form your next steps. Even when I’m fairly stubborn on A > B, this has been surprisingly effective at changing my mind.
Knowing when to not use AI — There are inherent risks to using AI for decisions due to limitations, bias, lack of context, etc. I’ll typically think through the worst case scenario of a poor decision and how people impacted by it would feel about the fact that AI was used in large part to make the decision. Higher criticality correlates with more manual review, and higher sensitivity means even if I think AI could make a better decision, I’ll rely mostly on my own priors and opinions.

Preserving my voice and quality
Despite my AI-nativeness, I actually really dislike “GPT-smell” and understand the frustration I see in the comments section of posts that were obviously ChatGPT written. They are often generic, overly verbose, take on a weird tone, and just generally feel like a tax on the reader. I also see cases where a push to “use AI for XYZ” results in an unintended trade-off in the quality of the output (i.e., the intent was to use AI for XYZ at the same quality).

For things I write, I’ve settled on three types of outputs:
Handcrafted Notes (0% AI-generated)
When: The audience is sensitive to AI-generated content, I think my raw notes would make sense to the readers, time+effort is not a concern, and/or I consider the document context for other prompts (and needs to be grounded completely in my opinions).
Examples: This blog, small group meeting notes, quick slack messages.
AI-aided Documents (80% AI-generated)
When: Most things I write — often leaning heavily on prompt context around what I know, what I want, and my own personal writing style. While it’s AI-generated, I consider the quality of the document to be “owned” by me and expect it to be at the same level as if I had written it myself. Often I think of these docs as different “views” of my raw notes, just LLM-transformed for different formats and audiences. For any given transformation, I aggressively aim to reduce consistent follow up edits by adding all my preferences to the transformation prompt itself.
Examples: Tech designs, non-substack blog posts.
Vibe Docs (100% AI-generated)
When: I don’t think the audience cares if it’s AI generated, I want to provide a skimmable example or strawman, and it’s time-sensitive yet low ROI. I’ll typically make it abundantly clear the document was AI-generated.
Examples: Linkedin posts, the-docs-already-answer-this slack messages.
There’s definitely a balance between doing things the old-fashioned way and spamming vibe docs. Ultimately, it seems reasonable to promote AI for targeted efficiency while holding folks accountable for the quality of their outputs (i.e. investing time into how to make AI actually make something useful, getting to this is not free but it is less work in the long run).
My AI subscriptions
Wanting to stay ahead on AI and being a SWE in AI SaaS naturally lends itself to spending a lot on AI tools. My guidance for most people would be to have a tool for general chat+search (e.g. one of ChatGPT, Perplexity, Claude, Gemini, etc.) and potentially a specialized one for your domain of work (that’s hopefully covered by your company). You’ll see plenty of reviews online like “X tool is unusable” or “Y is way better than Z,” but to be honest (not sure if this is a hot take), they are all at a pretty similar level of capability.
My average monthly costs for AI tools:
Perplexity ($20) — for search/research
Gemini Ultimate3 ($125) — for chat and Veo 3
Suno/Elevenlabs ($15) — for entertainment
Cursor4 ($200) — for coding
Vast.ai/Modal ($100) — for experiments
Perplexity/Anthropic/OpenAI API ($400) — for self-hosted chat and experiments
For quite a few workflows, I’ll start with exploring an idea for how to use an LLM in just a normal chat, move it to a custom GPT/Gem, and then eventually scale it to some custom scripts that directly hit the APIs. Mostly using OAI o3-high, gemini 2.5-pro, and Sonnet 4 max-budget which obviously drives up costs.
… It’s definitely a lot but to me the amount of work these tools can grind out and the value of learning-by-building on these is trivially worth it.
General tips & tricks
There are plenty of online resources for getting better at using AI assistants so I wont write out everything but these are my three core chat “prompting” techniques (that I often don’t see other people doing).
Encode core concepts into text-based documents and use these liberally.
An everything-about-me, everything-about-my-team, everything-about-this-project documents. Need to build a roadmap? “<roadmap-format> <team> <strategy> <project 1> <project 2> … Help me build a roadmap.“ Often this looks like me just copy-pasting directly into the Gemini chat window.
Prefer concept+preference documents over writing long prompts so most things just become transformations like “<source documents>, <output document>, plz convert“. Where “<output document>” is the format and preferences for how the output should be filled out. My actual “prompt” is just telling it to convert from one to the other.
Try not to think too hard about “prompting an AI” when writing these. With today’s models most advice comes down to just being articulate and mindful of assumptions which is pretty correlated with just writing good human-facing content as well. The key difference is that these concept documents can be rawer and longer.
Be mindful how complex your questions are and pre-compute context to improve consistency.
Even with reasoning models, the “thinking budget” is limited and certain questions may push these to the edge leading to a half-baked result. To work around this, you can be more strategic in how you ask questions and format documents to get 100% of the capacity of the thinking budget.
When building your concept docs, consider what mental overhead is required to actually apply them and add that to the document. It’s a bit unintuitive but an extremely common example is “Write <topic> in the same style as <examples 1, 2, 3>”. This requires the LLM to spend tokens on both understanding the examples and then applying them to the topic. Instead, I would first do “Explain in detail the style, voice, etc. of <examples 1, 2, 3>” and then do “Write <topic>, in <style-explanation>”. Often I refer to this as converting examples into policy.
For questions that follow a sequential workflow or are multi-part, you can build your prompt to do things step-by-step. For example: “Write <topic> in <format>, start only with step 1,” then “ok now step 2,” and so on. This works because the thinking budget typically resets after each user input.
Use LLMs for writing prompts for other LLMs.
I find that especially for text-to-video and text-to-audio models, the results of self-prompting vs first “I want XYZ, write a prompt for a text-to-video model“ and using the result as the input are radically different. This is often true for other text-to-<domain> applications, especially when your converter model is much smarter than the one used in the domain-specific app. I do this a ton for Suno, Veo 3, and Perplexity research.
It can be also useful to have an LLM rephrase and explain a prompt or concept doc back to you. If “what is the key takeaway of <concept document>” doesn’t align with your actual intent, it’s a useful indicator of missing context or assumptions.

Dependence on AI
Clearly the trend is that we are becoming increasingly reliant on these AI systems which can be a bit spooky. For work (as a SWE), I don’t really have any qualms about it. It just doesn’t feel very meaningful to spend time on a skill that’s increasingly automated (both writing code and the other parts of the role). If there’s a major AI outage in the future, I probably just won't be able to do any work that day.
Does AI make us dumber?5 Given how much I use it, surely my IQ would have dropped a decent amount by now but of course it’s non-trivial to self-evaluate that. A lot of the research I’ve read points to people using less critical thinking when they have ChatGPT and that using less critical thinking makes you dumber which seems pretty reasonable. However, I’ve also seen the expectations for a given role increase with the use of AI, which optimistically counteracts this (i.e., a given salary maps to a certain amount of human critical-thinking-compute; as AI does more decision-making, the areas for human computation shift).
Isn’t it weird to spend so much time chatting with an AI? You might think that from reading this post, I’m hinting at a future where our entire lives are just asking ChatGPT basic questions for literally everything. Anecdotally, as the percentage of my day spent with an AI assistant continues to increase, the total amount of time I feel the need to be on a screen has actually gone down. I attribute this to less time spent working (because AI is doing the heavy lifting during those busy weeks where I would’ve worked extra hours) and because most of what I was doing (research, coding, etc.) is just less meaningful with AI. Extrapolating this anecdote, and not that it’s necessarily where I’d put my money, a potential future is closer to Max Tegmark’s “Libertarian Utopia,” where AI-powered industry funds a human-centric, low-tech lifestyle6.

It might feel weird to spend so much time chatting with an AI, but that chat is the new form of leverage. Forget being the smartest person in the room: the goal now is to be the best at directing the intelligence you can bring into it.
“But what most of what software engineers do isn’t even write code!!!” — I see this a lot online but I have yet to meet someone who uses this as a defense as a reason why AI won’t automate most of SWE. While yes, most of my time as a staff engineer isn’t spent on writing code anymore, quite a bit of what I do (and did) is directly due to the fact that groups of humans were needed to write code. If you have an oracle that can turn PRDs into code, this effectively makes nearly the entire traditional SWE role obsolete.
This is something I recently started and it’s slowly growing. It contains all the context that could be potentially useful for an AI-aided life decision: age/height/weight, personal goals, tools and things I own, preferences/values, occupation, etc. I am definitely curious about extending this to more biometrics and real-time context to see how useful that is. I think right now I’m willing to some extent trust OAI/Google/Anthropic to handle these types of data but still consistently consider the privacy risks here vs self-hosted local models.
I only really got this because I really wanted to play with Veo3 but I think it’s actually a pretty solid deal. You get a ton of additional google workspace perks and most importantly a lot of it extends to my family accounts (a key blocker from me subscribing to ChatGPT).
Estimated from the subscription cost and my additional usage. I main claude-4-sonnet-max for everything which can really add up. This subscription is all covered by my work.
I wrote this in the context of adults who are mainly augmented in their existing expertise with the rise of AI. It’s less obvious to me what the positive and negative impacts will be on children and K12 education over the next few years.
While many people today might end up in a sweet spot of getting paid more by working less (because they can effectively use AI to get work done), it’s less clear to me what happens to folks who are just not hired in the first place because of the overall efficiency gains.
Great article Shrivu. I can relate to a lot of the things you are wrriitng a about both on my daily job and also in general in my personal and artistic life (I am a failed musician who still make music).
I have two other interesting questions that I believe are adjacent to the set you created, and i would love to hear your opinion about.
First: what should we read? As manager, my job is to consume vast amount of information and to make (hopefully) good decision based on that. And of course to keep learning.
I heavily mean in AI to decide what to read and what not to read. I built my own provate shmmarization tool that runs locally (so it's 100% private) and heavily lean on it to learn new things. I found this improved my learning speed significantly. What is your take on this?
Second: as a manger, I'd like to think I still have a in depth knowledge of the tech ( I keep learning) and I constantly evolve my system design skills.i can still code but of course my code is horrible, as I have not coded full time for many years now. I found AI coding liberating as it allows me to use my skills to write good software.
My vision for the future is that AI will make me as good as Sr. SWE and will radically change how I manage and run teams. What are your thougs in this?
This is on par with what I've built over time on my own. Let me kindly ask you:
- is a lot of "I like to experiment" represent the amount you're spending on subscriptions? (rather than you feel they help you a lot)
Secondly, the absence of "This whole system feels like it could/should be parallelized to run and cherry pick the best outcomes over 10,000 chats" makes me want to ask:
- if you have thought about the flywheel, which would make what you're doing right now a greedy search style; without the benefit of cherry picking through even 100 attempts?