
How Cursor (AI IDE) Works
Turning LLMs into coding experts and how to take advantage of them.

Understanding how AI coding tools like Cursor, Windsurf, and Copilot function under the hood can greatly enhance your productivity, enabling these tools to work more consistently — especially in larger, complex codebases. Often when people struggle to get AI IDEs to perform effectively, they treat them like traditional tools, overlooking the importance of knowing their inherent limitations and how best to overcome them. Once you grasp their internal workings and constraints, it becomes a 'cheat code' to dramatically improve your workflow. As of writing this, Cursor writes around 70% of my code1.
In this post, I wanted to dig into how these IDEs actually work, the Cursor system prompt, and how you can optimize how you write code and Cursor rules.
From LLM to Coding Agent
Large Language Models
LLMs effectively work by predicting the next word over and over again and from this simple concept we are able to build complex applications.

Prompting early decoder LLMs (e.g. GPT-2) involved crafting a prefix string that, when completed, would yield the desired result. Rather than “Write a poem about whales” you’d say “Topic: Whales\nPoem: ” or even “Topic: Trees\nPoem: … actual tree poem …\nTopic: Whales\nPoem: ”. For code this looked like “PR Title: Refactor Foo Method\nDescription: …\nFull Diff: “ where you constructed a prefix that when complete would implement what you wanted. “Prompt engineering” was creatively constructing the ideal prefix to trick the model into auto-completing an answer.
Then instruction tuning was introduced (e.g., ChatGPT), making LLMs significantly more accessible. You can now say “Write a PR to refactor Foo” and it would return the code. Under the hood, it is almost literally the same auto-complete process as above, but the prefix has changed to “<user>Write a PR to refactor Foo</user><assistant>” where the LLM is now acting in a chat. Even today, you’ll see weird cases where this fact leaks out and the LLM will start writing questions to itself by continuing to auto-complete past the “</assistant>” token.
When the models got big enough, we took it a step farther and added “tool calling”. Instead of just filling in the assistant text, in the prefix we can prompt “Say `read_file(path: str)` instead of responding if you need to read a file”. The LLM when given the coding task will now complete “read_file(‘index.py’)</assistant>”, we (the client) then prompt again with “<tool>… full contents of index.py …</tool><assistant>” and ask it to continue to complete the text. While it is still just an auto-complete, the LLM can now interact with the world and external systems.
Agentic Coding
IDEs like Cursor are complex wrappers around this simple concept.
To build an AI IDE, you:
Add a chat UI and pick a good LLM (e.g. Sonnet 3.7)
Implement tools for the coding agent
read_file(full_path: str)write_file(full_path: str, content: str)run_command(command: str)
Optimize the internal prompts: “You are an expert coder”, “Don’t assume, use tools”, etc.
And that at a high-level is pretty much it. The hard part is designing your prompts and tools to actually work consistently. If you actually built it exactly as I described, it would kind of work, but it would often run into syntax errors, hallucinations, and be fairly inconsistent.
Optimizing Agentic Coding
The trick to making a good AI IDE is figuring out what the LLM is good at and carefully designing the prompts and tools around their limitations. Often this means simplifying the task done by the main LLM agent by using smaller models for sub-tasks (see my other post Building Multi-Agent Systems).
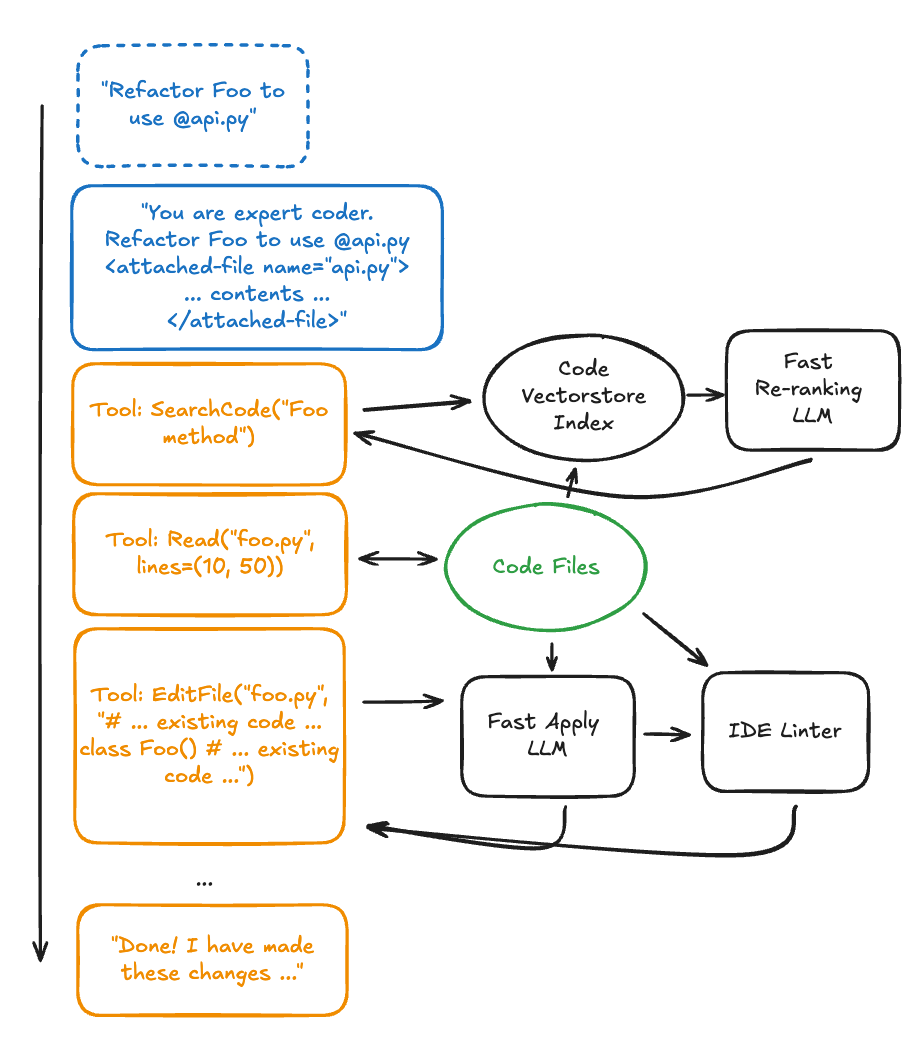
Optimizations & User Tips
Often the user already knows the right files or context, so we add an “@file” syntax in the Chat UI and when calling the LLM we pass the full content of all attached files with an “<attached-files>” block. This is syntactic sugar for the user just copy-pasting the entire file or folder in themselves.
Tip: Be aggressive about using @folder/@file in these IDEs (favor more explicit context for faster and more accurate responses).
Searching code can be complicated especially for semantic queries like “where are we implementing auth code”. Rather than having the agent get good at writing search regexes, we index the entire codebase into a vectorstore using an encoder LLM at index time to embed the files and what they do into a vector. Another LLM at query time re-ranks and filters the files based on relevance. This ensures the main agent gets the ‘perfect’ results to its question about auth code.
Tip: Code comments and doc-strings guide the embedding model which make them much more important than if they were just for fellow humans. At the top of files, have a paragraph for what the file is, what it semantically does, when it should be updated.
Writing character-perfect code is hard and expensive, so optimizing the write_file(…) tool is the core to many of these IDEs. Instead of writing the full contents of a file, often the LLM produces a “semantic diff” which provides only the changed contents with added code comments that guide where to insert the changes. Another cheaper, faster code-apply LLM takes this semantic diff as a prompt and writes the actual file contents while fixing any small syntax issues. The new file is then passed through a linter and the tool result to the main agent contains both the actual diff and the lint results which can be used to self-correct broken file changes. I like to think of this as working with a lazy senior engineer who writes just enough code in snippets for an intern to make the actual changes.
Tip: You can’t prompt the apply-model. “Stop deleting random code”, “Stop adding or deleting random comments,’ etc. are futile suggestions since these artifacts come from how the apply model works. Instead give the main agent more control, “Provide the full file in the edit_file instructions”.
Tip: The apply-model is slow and error prone when editing extremely large files, break your files to be <500 LoC.
Tip: The lint feedback is extremely high signal for the agent, you (and Cursor team) should invest in a really solid linter2 that provides high quality suggestions. It helps to have compiled and typed languages that provide even richer lint-time feedback.
Tip: Use unique file names (rather than several different page.js files in your codebase, prefer foo-page.js, bar-page.js, etc), prefer full file paths in documentation, and organize code hot-paths into the same file or folder to reduce edit tool ambiguity.
Use a model that’s good at writing code in this style of agent (rather than just writing code generally). This is why Anthropic models are so good in IDEs like Cursor, they not only write good code, they are good at breaking down a coding task into these types of tool calls.
Tip: Use models that are not just “good at coding” but specifically optimized for agentic IDEs. The only (afaik) leaderboard that tests for this well is the WebDev Arena3.
One (very expensive) trick I used in my own AI IDE sparkstack.app to make it much better at self-correction was to give it an “apply_and_check_tool”. This runs more expensive linting and spins up a headless browser to retrieve console logs and screenshots along the user-flows of the app to provide feedback to the agent. It’s in cases like this where MCP (Model Context Protocol) will really shine as a way to give the agent more autonomy and context.
Line-by-line Cursor System Prompt Analysis
Using an MCP-based prompt injection, I extracted the latest (March 2025) prompts used by Cursor agent mode. As someone who builds extensively on LLMs, I have a great deal of respect for the ‘prompt engineers’ at Cursor who really know how to write good prompts (imo) compared to what I’ve seen in other AI IDEs. This I think is a large reason why they are one of the leading coding tools. Diving into prompts like this is also a great way to improve your own prompts and agent architecting abilities — it’s great that in some sense most GPT wrappers are “open-prompt”.

“<communication>”, “<tool_calling>”, etc. — Using a mix of markdown and XML section tags improves prompt readability for both humans and the LLM.4
“powered by Claude 3.5 Sonnet” — Pretty often LLMs don’t accurately tell you what model they are running. Putting this explicitly reduces complaints that Cursor billing for a different model than what the LLM itself says is running.5
“the world's best IDE” — This is a succinct way of telling the LLM not to recommend alternative products when things break which can be pretty important for branded agents.6
“we may automatically attach some information…follow the USER's instructions…by the <user_query> tag.” — Rather than passing user prompts directly to the LLM, Cursor also places them into a special tag. This allows Cursor to pass additional user-related text within the <user> messages without confusing the LLM or the user.
“Refrain from apologizing” — Something they clearly added due to Sonnet’s tendencies.
“NEVER refer to tool names when speaking” — Cursor added this in bold and ironically I still see this often as “Using edit_tool”. This is an annoying issue with recent Sonnet models.
“Before calling each tool, first explain” — It can be a weird UX while the LLM is streaming a tool call because the chat looks stuck for a few seconds. This helps the user feel confident something is happening.
“partially satiate the USER's query, but you're not confident, gather more information” — LLM agents have a tendency for overconfident early stopping. It’s helpful to give them an out so they dig deeper before responding.
“NEVER output code to the USER” — By default LLMs want to produce code in inline markdown codeblocks so additional steering is required to force it to only use the tools for code which are then shown to the user indirectly through the UI.
“If you're building a web app from scratch, give it a beautiful and modern UI” — Here you see some demo-hacking to produce really flashy single-prompt apps.
“you MUST read the the7 contents or section of what you're editing before editing it” — Often coding agents really want to write code but not gather context, so you'll see a lot of explicit instructions to steer around this.
“DO NOT loop more than 3 times on fixing linter errors” — Aimed to prevent Cursor getting stuck in an edit loop. This helps but anyone who uses Cursor a lot knows this is still pretty easy to get stuck in.
“Address the root cause instead of the symptoms.” — As a case of bad LLM-alignment often they’ll default to deleting the error message code rather than fixing the problem.
“DO NOT hardcode an API key” — One of many security best practices to at least prevent some obvious security issues.
Tools “codebase_search”, “read_file”, “grep_search”, “file_search”, “web_search” — Given how critical it is for the LLM to gather the right context before coding, they provide several different shapes of search tools to give it everything it needs to easily figure out what changes to make.
In several tools, “One sentence explanation…why this command needs to be run…” — Most tools contain this non-functional parameter which forces the LLM to reason about what arguments it will pass in. This is a common technique to improve tool calling.
Tool “reapply” that “Calls a smarter model to apply the last edit” — allows the main agent to dynamically upgrade the apply model to something more expensive to self-resolve dumb apply issues.
Tool “edit_file” states “represent all unchanged code using the comment of the language you're editing” — This is where all those random comments are coming from and this is required for the apply model to work properly.
You’ll also notice that the entire system prompt and tool descriptions are static (i.e. there’s no user or codebase personalized text), this is so that Cursor can take full advantage of prompt caching for reduced costs and time-to-first-token latency. This is critical for agents which make an LLM call on every tool use.
How to Effectively Use Cursor Rules
Now the big question is what’s the “right way” to write Cursor rules and while my overall answer is “whatever works for you”, I do have a lot of opinions based on prompting experience and knowledge of Cursor internals.

It’s key to understand that these rules are not appended to the system prompt but instead are referred to as named sets of instructions. Your mindset should be writing rules as encyclopedia articles rather than commands.
Do not provide an identity in the rule like “You are a senior frontend engineer that is an expert in typescript” like you may find in the cursor.directory. This might look like it works but is weird for the agent to follow when it already has an identity provided by the built-in prompts.
Do not (or avoid) try to override system prompt instructions or attempt to prompt the apply model using “don’t add comments”, “ask me questions before coding”, and “don’t delete code that I didn’t ask you about”. These conflict directly with the internals breaking tool-use and confuse the agent.
Do not (or avoid) tell it what not to do. LLMs are best at following positive commands “For <this>, <do this>” rather than just a list of restrictions. You see this in Cursor’s own prompts.
Do spend time writing highly salient rule names and descriptions. It’s key that the agent, with minimal knowledge of your codebase, can intuitively know when a rule is applicable to use its fetch_rules(…) tool. As if you were building a handcrafted reverse index of documentation, you should at times have duplicate rules with different names and descriptions to improve the fetch rate. Try to keep descriptions dense and not overly verbose.
Do write your rules like encyclopedia pages for your modules or common code changes. Like wikipedia, linking key terms (using mdc link syntax) to code files provide a huge boost to the agent when determining the right context needed for a change. This at times also means avoiding step by step instructions (focus on “what” and not “how”) unless absolutely necessary to avoid overfitting the agent to a specific type of change.
Do use Cursor itself to draft your rules. LLMs are great at writing content for other LLMs. If you are unsure how to format your documentation or encode context, do “@folder/ generate a markdown file that describes the key file paths and definitions for commonly expected changes”.
Do consider having a ton of rules as an anti-pattern. It’s counterintuitive but while rules are critical for getting AI IDEs to work on large codebases, they are also indicative of a non-AI-friendly codebase. I wrote more on this in AI-powered Software Engineering, but the ideal codebase-of-the-future is intuitive enough that coding agents only need built-in tools to work perfectly every time.
See some examples I generated.
Conclusions
It’s wild how a fork of VSCode, built on effectively open-source agent prompts and publicly accessible model APIs, could reach valuations approaching $10B — carrying a "wrapper multiple" of 68 . It will be interesting to see if Cursor ends up developing it’s own agentic models (feels unlikely) or if Anthropic will just swoop in as a competitor with Claude Code + the next Sonnet.
Whatever ends up being the case, knowing how to shape your codebase, documentation, and rules will continue to be a useful skill and I hope this deep dive gave you a less ‘vibes-based’ and more concrete understanding of how things work and how to optimize for AI. I say it a lot and I’ll say it again, if Cursor isn’t working for you, you are using it wrong.
This is a vibes-based statistic but I don’t think it’s far off. Once you get good at Cursor rules, a decent amount of PRs literally just become one-shot prompts. I originally thought it would take until 2027 to get here but between the Anthropic, Cursor, and my own prompt-foo improving simultaneously, things are improving faster than I guessed.
I’ve been really impressed with CodeRabbit’s linting so far and plan to use MCP to pass that back into Cursor. If Cursor’s default linter were better, with everything else remaining the same, it would feel like using Sonnet 3.8.
The beauty of (most) LLMs is that while this is a web dev benchmark, the performance in my experience heavily correlates with all types of coding and frameworks.
I was unable to find a scientific study on this, but based on my experience, this works really well, and I wouldn’t be surprised if Anthropic models are explicitly trained on pseudo-XML syntax.
This does have some unintended side effects where the coding model will change model names referenced in your codebase to be the same as itself.
There’s an interesting legal gray area here. It would actually be illegal (see FTC Act, Lanham Act) for Cursor to put this on their website and yet it’s fine (for now) for them to put it in a prompt and have the LLM say it on their behalf.
FYI Cursor team I found a typo (:
It’s a term I’ve made up for the ratio between the valuation of a GPT wrapper and the model provider. In this case, Anthropic : Cursor = $60B : $10B = 6. My gut tells me that “6” is not a rational ratio. With my unsophisticated investor hat on, I’d speculate Anthropic should be closer to $100B and Cursor as high as $1B (a wrapper multiple of 100). It’s just hard for me to see how either of them really have a long term moat and it seems trivial for Anthropic to build their own next generation AI IDE competitor.
Great Article. I wonder how much "Code comments and doc-strings" actually matter.
Overall, I love using Cursor/Claude 3.7, but it’s easy to become overly reliant on these tools. While LLMs can occasionally generate bull, they’re still fantastic for quickly grasping new concepts.
Awesome article!