
Socioeconomic Modeling with Reasoning Models
Using a complex political simulation game to test state-of-the-art reasoning models.

Try this out at state.sshh.io (GitHub) [update May 2025: no longer running]
For the past few weeks, I’ve been trying to find ways to pressure test the latest generation of “reasoning” Large Language Models1 and I ended up turning my latest experiments into a competitive political simulation game called “State Sandbox”.
I’m a huge fan of using toy video games as a way to explore emerging technologies (see Infinite Alchemy and Terrain Diffusion) since they are fairly low stakes and literally gamify exploring the limits of the latest models. For my latest experiments, I wanted to find out:
How “production-ready” are the latest reasoning models?
What are the design considerations for migrating from non-reasoning models (e.g. OpenAI’s gpt-4o)?
How much value does built-in “reasoning” provide over explicit CoT prompting?
Are they actually that smart (aka PhD level)?
So here’s my write-up on both the game and some of my takeaways with OpenAI’s o1 and o1-mini.
State Sandbox

Inspired by some of my favorite childhood games (Civilization, NationStates) and the recent widespread discussion of executive orders after the 2024 US election, I thought it would be interesting to build effectively an “executive order simulator”. As the leader of a fictional country, you’ll get to handle ongoing national challenges and take arbitrary executive actions and see how this plays out. Unlike Civilization and NationStates, the actions you take and their effects are truly arbitrary as the core game engine is powered just by a large reasoning model. You could go as far as copying an actual executive order into the game and it will “simulate” it.2
To play:
You select a country name and a set of values that seed the various aspects of the country. A fictional country is then generated based on these choices. Using AI, it’s heavily customized including the nation’s cultural practices, its economic sectors, crime rates, and health statistics. To make things interesting, the in-game world references real life countries as international partners while inventing a unique primary religion and ethnic group for the user’s nation.
Using the unique characteristics of the country, AI is used to synthesize natural events (hurricanes, protests, sanctions, etc.) that will occur in the next year.
As the player, you have an open-ended text box to type in your actions and responses to these events (you can also provide actions unrelated to events).
You click next turn and after a few minutes, the dashboard refreshes showing you all the changes that occurred that year along with a summary report. The cool part is that the changes are complex and granular — a policy that encouraged domestic oil production could impact your CO2 emissions, reduce trade with certain international trade partners, and even increase the percentage of deaths caused by car accidents.
To make it a bit competitive, I also added a leaderboard so you can complete against other players on various metrics like annual GDP, population, and World Happiness Score. Generally, it would be really cool to see other games, like Risk, have an AI spin that allows you to take more unbounded natural language turn actions.
How It Works
Simulation
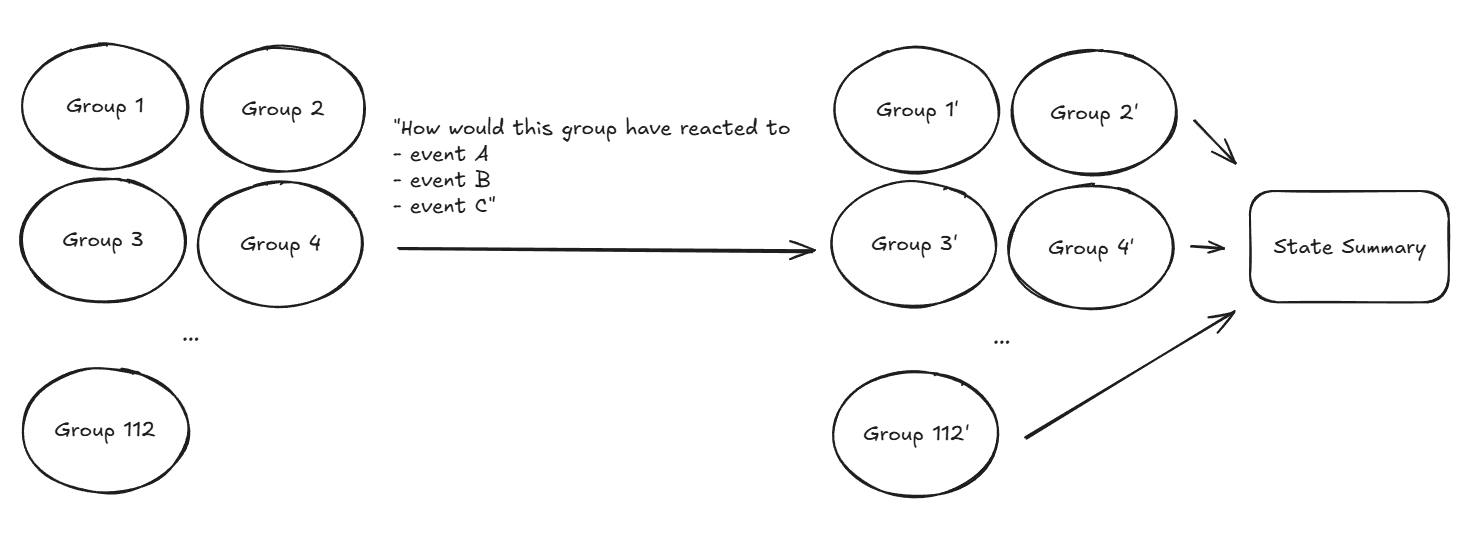
My initial idea was to have an “agent” for every N members of the population similar to other LLM-based human behavior simulations. So for a population of 28 million, N = 0.25 million, you’d have 112 agents that would individually react to the events and policies and I’d use another agent to summarize this into the dashboard. This failed to capture nation-wide metrics that I was hoping to model like trade relationships, social movements, etc. as it was awkward to consider these as characteristics of any one individual group. From a cost perspective, this also didn’t really seem feasible as increasing the granularity of the groups meant running these reasoning models thousands of times per turn.

My second attempt was the Wikipedia-page approach, instead I encode the state of the game as an extremely detailed encyclopedia page. Each simulation turn then just re-writes the entire page (see example content). This also takes better advantage of the reasoning model’s capability to holistically evaluate the changes to the entire nation during the year. This worked well until I ran into some core issues:
OpenAI’s o1 (the reasoning model I was using) would struggle with these extremely long structured outputs — not that it was formatting it wrong, it just didn’t want to generate the entire thing (e.g. “… and the rest”) even with space in the context window.
o1 struggled with “holistic diffs” to the massive structure, it would be great at first-order changes but if the policies and events were mainly around cultural policies it would (no matter how hard I pushed) forget to also consider that the GDP should change at the country’s expected GDP growth rate.
The latency of both reasoning and decoding the full output was extremely slow — so much so it wasn’t that fun to play anymore.
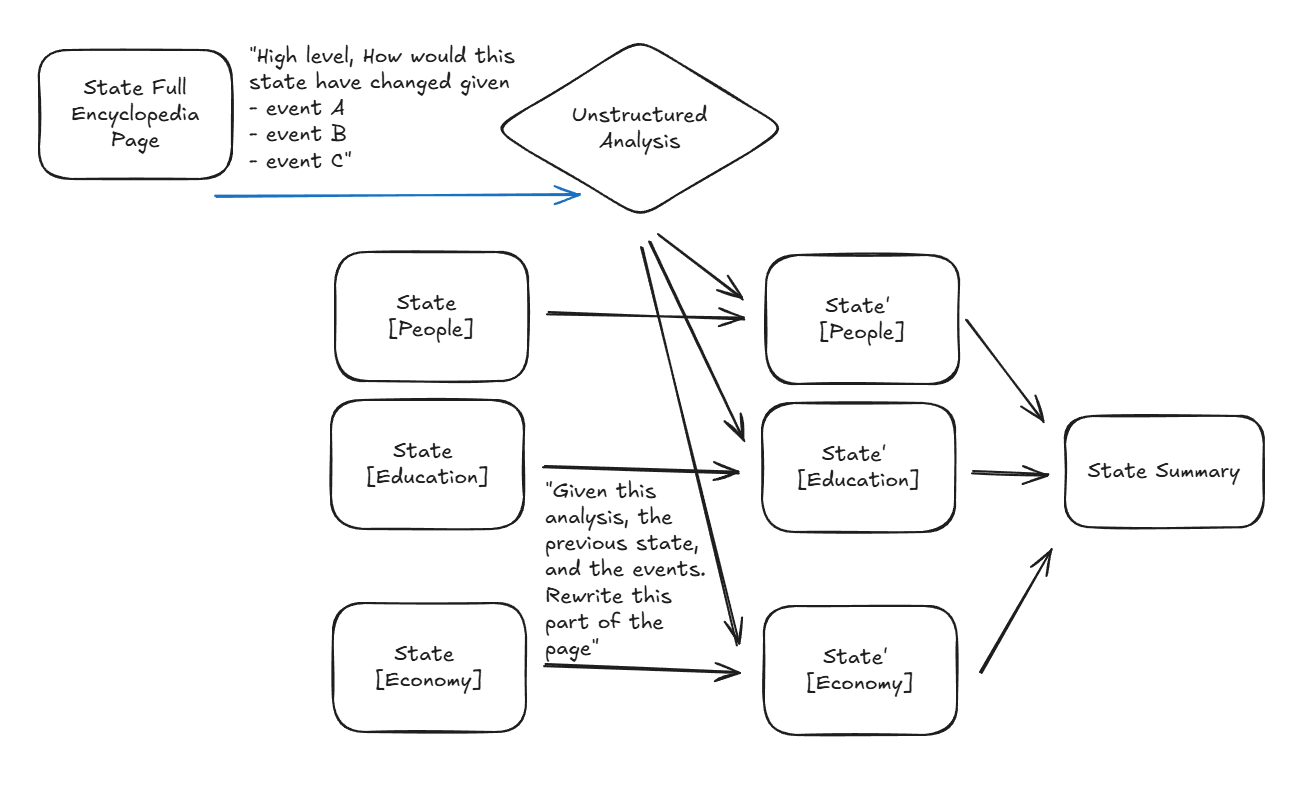
A lot of these issues reminded me a lot of some of the pain points I saw with AI IDEs where you have a complex change that might re-write several very large files. It’s token inefficient, error-prone, and slow to make the “primary” (o1) model code everything and so instead you have a “primary” model free-form describe what’s important and then parallelize structured file changes among “secondary” models (o1-mini). This way you get the best of both worlds as the smart model holistically orchestrates the key changes (see example) and then high-token-structured-output work is passed to more efficient models.

To keep the randomness random, o1 provides a menu of potential events and this is parsed and sampled using an actual random number generator rather than just asking o1 to pick the events itself. These events also take as an input the state encyclopedia page to provide better priors (e.g. large industrial sector makes industrial problems more likely).
I also post-process all distribution tables (e.g. the percentage breakdown of various ethnic groups) in the structured o1-mini encyclopedia output to force them to actually add up to 100%.
The Stack
I borrowed the Next.js + FastAPI boilerplate from my building-v0-in-a-weekend-project and pretty much 90%+ of the code and prompts for this were all written by the Cursor IDE. The initial UI mock ups were done just on my phone using Spark Stack. Ironically this is my 4th project with Next.js and I still don’t totally know how to use it, but I guess I don’t really need to since AI does well enough.
One cool use of Cursor was generating the sheer number of dashboards and charts for every distinct panel (People, Education, Health, etc.) in the game. I just gave it the raw game state JSON object and it was able to build pretty clean dashboard pages for all the content. This would have easily taken 10x longer had I tried to do this manually and ended up being pretty neatly organized.
Learnings from OpenAI’s o1 and o1-mini
My main goal was to push these models with fairly complex simulation tasks and very high token structured inputs and outputs — here are a few takeaways from this experience.
The o1 and o1-mini APIs are still a little sketchy
While markdown has been the language of LLMs, I can get neither of these models to reliably produce consistent markdown or not markdown. 3
They don’t yet reliably support some core features like streaming, function calling, system prompts, images, and temperature.
For at least a few weeks, OpenAI advertised o1 availability for Tier 5 users — when they did not indeed yet support full o1.4
PhD-level might be a stretch
I have a lot of empathy for LLMs, so I’ll preface that these are all mitigatable challenges but it’s important to call out some examples of “intelligence” not so out of the box with these models.
o1 fails (~ 1 in 10 times) to generate short syntactically valid SVG code (used for state flag generation) — I have yet to see Anthropic’s Sonnet get this wrong.
o1 fails (~ 9 in 10 times) to update a list of just a few whole number percentages in a way that keeps them summing up to 100%
o1 has a strong what I’ll call left/utopia bias (likely an artifact of how OpenAI aligns these models) and while that might work for their ChatGPT product, it does make it do some silly things in the context of simulation. As an example, premised with an ad absurdum conservative country, it would still try to inject a flourishing LGBTQ community. That’s nice… but obviously not correct and I would expect the output in this context to be independent of the ethics of the model.
Reasoning strength and token utilization are interesting
The tokens spent reasoning (for a given “reasoning strength” level) are far more consistent than I expected, even with “carefully consider A, B, C, …”, “think about (1) (2) (3), ...” to try it get it to reason more, I’d still get fairly consistent token utilization and latency.
This is a production blessing because it does seem to mitigate the issue of a reasoning-DoS attack. A user can’t (as far as I can tell) give your customer support bot a frontier math problem to run up costs.
This does have downsides when you want the reasoning strength to be flexible or dynamic to the complexity of the request. I’m hoping the nice folks using ChatGPT Pro are providing good training data for an “auto” reason strength feature.
With large inputs, outputs, and complex problems you run into interesting trade-offs to stay within the models context window (which is computed as input + reasoning + output). There may be some cases where you have to give the model less useful input context in hopes it can just figure it out as part of its reasoning token space.
More reasoning tokens consistently led to better instruction following which is a very nice behavior to have. It seems there may be linear relation between “# of reasoning tokens” and “# of independent instructions the model can follow correctly”.
Besides instruction following, it was unclear from my experiments how reasoning strength/tokens related to the “intelligence” of the model. My mental model so far is that the reasoning is akin to an LLM-driven brute force test + verify technique — which is much less magical than other descriptions I’ve heard. It’s possible it’s also just too early to judge these RL/test-time training techniques and we’ll see more “emergent” behavior with o3.
These reasoning models did not get rid of a need for CoT prompting but it did change how I write these prompts. Even with high reasoning o1 and o1-mini didn’t seem to have enough time to think to solve the simulation outcomes. Rather than “show your thoughts”, I ended up providing more structured output requirements that force it to answer guiding questions before responding. This boosted efficacy and provided significantly more explainability than the blackbox reasoning on its own.
Mini reasoning models are incredible
o1-mini felt very competitive with o1, much more so than previous mini/non-mini model pairs. My hypothesis is that test-time compute makes these distilled/quantized versions perform much closer to their full weight counterparts with the ability to also use more reasoning-tokens-per-time to be at times even more performant.
This also means that when o{n} comes out, I expect it’s going to be much less notable when o{n}-mini does. When o1-mini has more reasoning modes available, I’m not sure why I would use o1. I expect the same will be true of o3.
This seems to be replicated on many of the leading benchmarks as well, with o1-mini much closer if not higher than o1 full.
This is a very promising for the next generation of open-source self-hostable (<70B parameter) reasoning models which may strategically trade-off higher reasoning latency with lower parameter counts for equal performance to larger models.
Conclusions
o1 and o1-mini show potential but still have issues with bias, consistency, and reliability, making them not entirely “production-ready”.
o1-mini performs on par or better than the full o1 model and significantly improves on the instruction following compared to non-reasoning alternatives.
Try this game (and o1) out at https://state.sshh.io/!
I drafted this before DeepSeek R1 which also shows impressive benchmark performance. I still expect quite of few of the takeaways to remain the same for these other reasoning models.
I’ll leave it to individual users to decide if the simulation is “accurate” or not. At some point, the simulation complexity surpassed what I myself can verify and unlike a math proof or a crypto puzzle there’s not going to be a clear ground truth answer.
The docs state that starting with o1 they won’t default to markdown — which is fine but also my expectation is that they will not then produce markdown (especially with prompts for “Use plain text”) but they still do. I just want consistency.
This was verified with OpenAI official support (who also seemed somewhat confused about this). Definitely not a good look to “launch” something officially but not actually do it.