
Speculations on Building Superintelligence
Predictions on superintelligent AI based on what we know in 2023.

Large language models (LLMs) like GPT-4 are getting surprisingly good at solving problems for unique unseen tasks in a notable industry shift from specialized models (those trained for a specific domain, specialized dataset, to provide a specific set of outputs) to those with task-agnostic and prompt-able capabilities. So much so that many are beginning to extrapolate that if these models continue to improve they could soon reach the capabilities of general human intelligence and beyond.
The concept of intelligent "thinking" machines has been a topic of discussion since the 1960s, but the practical implementation of Artificial General Intelligence (AGI) was considered somewhat taboo in the Machine Learning industry until recently. With the development of models surpassing the 100 billion parameter mark and the impressive capabilities they've demonstrated, the idea of AGI is becoming increasingly plausible. This is evident in OpenAI's mission statement, which now includes a reference to the creation of an "artificial general intelligence".

In addition to the mainstream adoption of AI-powered tools like ChatGPT, the growing interest in the capabilities, impact, and risks of AGI is reflected in the online group r/singularity's membership surge to over 1.5 million members. The group's name alludes to the "singularity event", a hypothetical future point when AI not only achieves human-level intelligence but reaches a level where “technological growth becomes uncontrollable and irreversible”.
In this article, we help define the concept of "superintelligence", explore potential methods and timelines for its construction, and provide an overview of the ongoing debate surrounding AI safety.
Defining “Superintelligence”
Unlike regression and classification tasks which can be measured in terms of some type of numerical error, “intelligence” is a much more undefined concept. To measure today’s LLM capabilities researchers have used a mix of standardized tests (similar to the SAT), abstract reasoning datasets (similar to IQ tests), trivia questions, and LLM vs LLM arenas. The “intelligence” of the model is then its average correctness across these tasks or its relative performance to other models and a human baseline.
On the more philosophical end, you have the Turing Test which gets around the ambiguity of whether a machine is “thinking” with a challenge to distinguish between players A and B, one of which is a machine, by only passing notes back and forth. If the machine can reliably fool the integrator into believing it is the human, then we consider it intelligent. With some interpretation of the requirements for winning, GPT-4 already can reliably pass open-ended chat-based Turing Tests. There’s also the question of if a machine passes this type of test, is it conscious? This is famously argued against in the Chinese Room Argument which states that there’s a fundamental difference between the ability to answer open-ended questions correctly (possible without a world model via memorization) and “thinking” (requiring some level of consciousness). Overall, consciousness is still more of a philosophical question than a measurable one.
As for Artificial General Intelligence (AGI) and Superintelligence (ASI), the definitions of these are hotly debated. For the most part, AGI refers to “as good as human” and ASI refers to acting “far more intelligent than humans” (therefore any ASI would be an AGI).
[Superintelligence is] an intellect that is much smarter than the best human brains in practically every field, including scientific creativity, general wisdom and social skills
Nick Bostrom in How Long Before Super Intellegence
From Superintelligence: Paths, Dangers, Strategies, you can also break superintelligence into different forms of “super”:
A speed superintelligence that can do what a human does, but faster
A collective superintelligence that is composed of smaller intellects (i.e. composing a task into smaller chunks that when solved in parallel constitute a greater intelligence)
A quality superintelligence that can perform intellectual tasks far more effectively than humans (i.e. the ability to perform not necessarily faster but “qualitatively smarter” actions)
You can also look at it in terms of the percentage of humans that a machine can surpass and for what range of tasks. DeepMind’s “Levels of AGI” provides a framework that breaks it down between performance and generality:
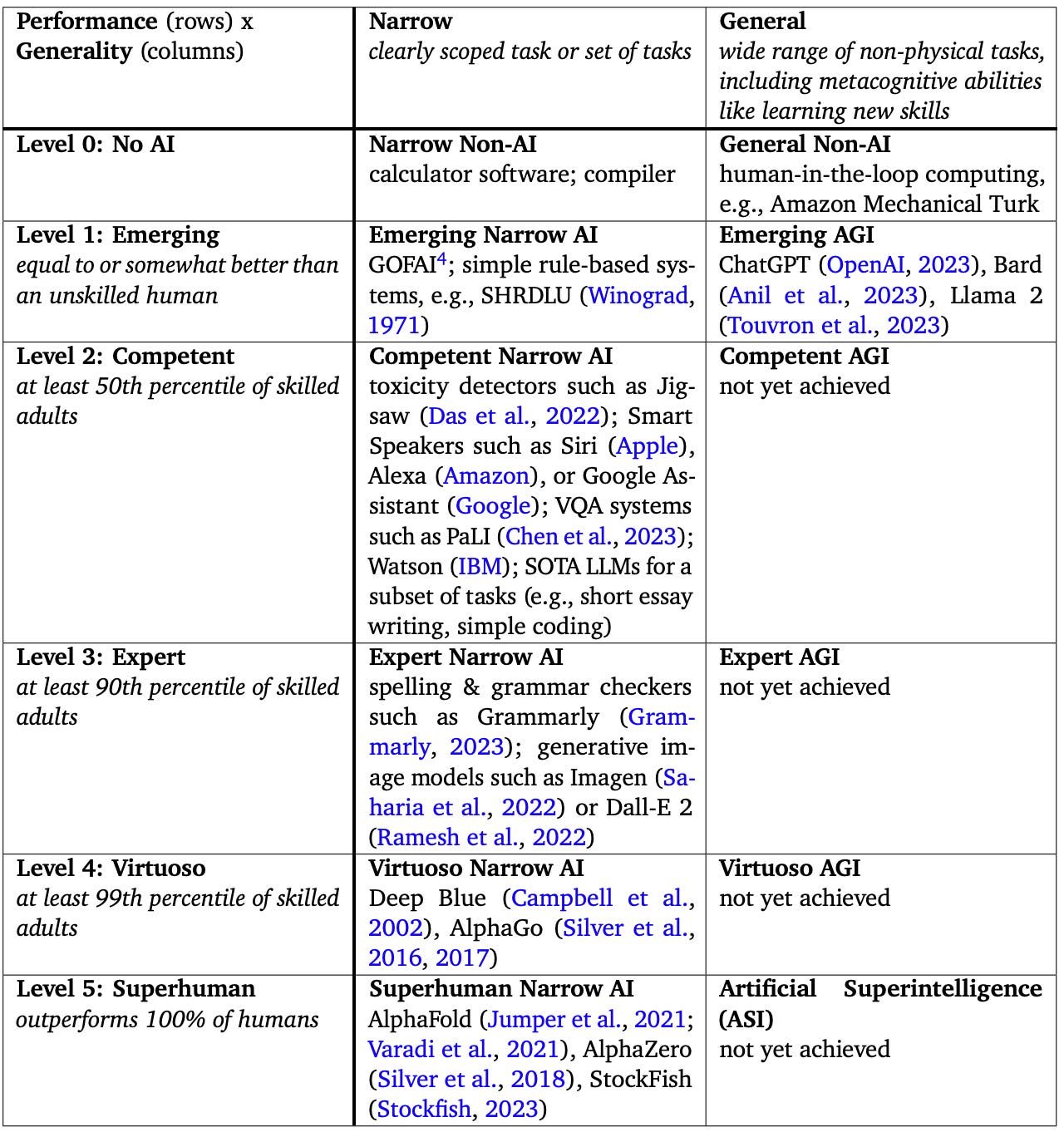
In this, we say:
AGI = >50%ile of skilled adults over a wide range of general tasks
ASI = better than all humans over a wide range of general tasks
It’s important to note that for the most part with these definitions:
We don’t include any physical tasks in those used to measure general intelligence. This means an AI system that acts within a ChatGPT style text-in text-out form could still fundamentally be superintelligent depending on how it answers a user’s questions.
We also don’t (yet) define the evaluation criteria for “solving” a task or who/what is qualified to make that judgment.
We don’t expect ASI to be omnipotent or “all knowing”. It can perform better than humans but it can’t do anything. It can’t predict truly random numbers or perfectly reason about a contrived topic it was never exposed to.
We’ll for the most part accept superintelligent but slow responses. Taking a week to answer a prompt better than any human is still ASI.
Predictions
Now that we’ve defined superintelligence, we can decide whether it’s science fiction or a realistic future extension of the rapid progress we’ve so far seen in Machine Learning. I think it’s too early to make any definitive conclusions but I do offer some opinionated beliefs/speculations/guesses as to what we might see in the next few years for AGI/ASI.
Prediction 1: Next-Token Prediction Is All You Need
Modern generative language models are a form of “next-token predictors”. At a high level, to produce a response they look at the previous words and choose the statistically most likely next word over and over until the next word is [END-OF-STRING] (a special token that signifies the text is over). This process is also referred to as “auto-regressive” as after the first word is generated, the model uses its own previous outputs as the previous words to make its next prediction. Because of this, critics often referred to even seemingly intelligent models as “stochastic parrots” and a “glorified autocompletes”.

However, as OpenAI’s Sutskever puts it, “Predicting the next token well means you understand the underlying reality that led to the creation of that token”. In other words, you can’t downplay how “intelligent” a next token model is just based on its form — to reliably know the correct next word in general contexts is to know quite a bit about the world. If you ask it to complete “The following is a detailed list of all the key presses and clicks by a software engineer to build XYZ:“, to reliably provide the correct output (or one indistinguishable from a human) is to be able to understand how an engineer thinks and the general capability to build complex software. You can extend this to any job or complex human-operated task.
Researchers have also proven that auto-regressive next-token predictors are universal learners and are computationally universal. This can be interpreted to mean LLM (or variants) can fundamentally model any function (like completing a list of words encoding actions taken by a human on a complex task) and compute anything computable (running any algorithm or sequence of logic statements). More complex problems may require more “thinking” in the form of intermediate words predicted between the prompt and the answer (referred to as “length complexity”). Today we can force the LLM to perform this “thinking” by asking it to explain its steps and researchers are already exploring ways to embed this innately into the model.
The next-token form can also be augmented with external memory stores or ensembled as a set of agents that specialize in specific tasks (i.e. collective intelligence, like a fully virtual AI-”company” of LLM employees) that when complete solves a general problem.
My first prediction is that GPU-based auto-regressive next-token predictors, like but not exactly like modern LLMs, can achieve AGI/ASI. The underlying tokens may not be words and the model may not be transformer-based but I suspect this form will be enough to achieve high-performance general task capabilities. This is as opposed to requiring a more human brain-inspired architecture, non-standard hardware like optical neural networks or quantum computing, a revolutionary leap in computing resources, symbolic reasoning models, etc.
Prediction 2: Copying Internet Text Is Not Enough
Nearly all LLM’s are trained in two phases:
Phase 1: Training the model to get very good at next-token prediction by getting it to copy word-by-word a variety of documents. Typically trillions of words from mixed internet content, textbooks, encyclopedias, and high-quality training material are generated by pre-existing LLMs.
Phase 2: Fine-tuning the model to act like a chatbot. We form input documents as a chat (“system: …, user: …, system: …”) and train the parameters of the model to only complete texts in this format. These chats are meticulously curated by the model’s creator to showcase useful and aligned examples of chat responses.
With these two phases, our modern LLMs can perform at the level of “Emerging AGI” — models that can solve general tasks at an unskilled human level. However, when we look at today’s narrow (non-general) superhuman models, like AlphaGo, they are trained very differently. Rather than being trained to copy human inputs, they use a reinforcement learning technique known as self-play where the models are pitted against each other thousands of times, improving on each iteration and eventually surpassing human performance. The improvement comes from providing the AI a “reward” that is carefully propagated back into the weights of the model so it’s even better the next time. Most importantly, by playing against itself as the primary drive of self-improvement, it can adapt strategies that are beyond what would be possible simply copying human play.
My second prediction is that some form of unsupervised self-play will be required to achieve ASI. This means we’ll potentially have phase 3, where the model exists in a virtual environment with a mix of human and other AI actors. Given a reward for performing “intelligently” within this environment, the model will gradually surpass human capabilities. This is potentially analogous to the innate knowledge of a newborn (phases 1 and 2) vs the knowledge gained over living experience (phase 3).
How one actually computes a reward for intelligence and what this environment entails is a non-trivial open question. My naive construction would be an AI-based Q&A environment (i.e. AI Reddit) where hundreds of instances of the model ask, answer, and judge (with likes/upvotes) content. The rewards would be grounded in some level of human feedback (potentially sampling content and performing RLHF) and a penalty to ensure they communicate in a human-understandable language. It’s very possible that too little human feedback would lead to a “knowledge bubble” where the models are just repeatedly reinforcing their own hallucinations. This could be mitigated by increasing the amount of content judged by humans and potentially exposing the model directly on an actual Q&A platform (i.e. real Reddit). In the case that this overfits tasks related to a Q&A environment, you’d want to give the model more and more diverse and multimodal domains to learn and self-interact.
Assuming this is the case, you can also make some interesting conclusions about how ASI would work:
Its intelligence would be bounded by experiences with versions of itself and humans, so while we can’t eliminate the chance of an intelligence explosion, the capabilities will measurably grow over time.
There might not be a super-AI gets “out-of-the-box” risk scenario as fundamentally phase 3 training would require interaction and exposure to the outside world.
The alignment of the model will be heavily tied to the formulation of the reward function. This means it probably won’t have the incentive to destroy humanity but could still find usefulness in deceptive/malicious actions that boost its score.
Due to self-play, while it may act in a way that’s rewarded and understood by humans, it may “think” and solve problems incomprehensibly differently.
Prediction 3: ASI in 5 to 30 Years
Arguably the most interesting question on the topic of AGI/ASI is when it will happen. My 90%-confidence interval on a controversial form of ASI (I have strong doubt that when ASI is first introduced everyone would agree it’s ASI) is somewhere between 5 to 30 years (2028 to 2053). I know for some, this is far too conservative given the recent advancements we’ve seen with LLMs, and for others, it’s silly to even believe this will happen in our lifetimes but ultimately time will tell.
Why it won’t be within 5 years:
The groups with the most compute to experiment with something like this are financially motivated to focus on sub-AGI models that solve concrete applications of AI.
Current LLMs are not good enough that simply more data, more computing, or minor variations to their structure on their own will be able to close the intelligence gap.
We still need time to achieve AGI as a prerequisite to ASI.
Why it won’t be more than 30 years:
Extrapolating the rate of progress we’ve seen in the field, it feels certain that we will have extremely powerful models in the next few decades.
Even given future AI safety regulations/concerns, enough actors should have the skills and computing to build this that one of them will do it despite the consequences.
As AI models improve and the possibility of ASI becomes more concrete, corporations (profit-motivated) and governments (national security-motivated) will begin to put significant funding into its development.
Intelligent AI Risks & Safety
There is no current consensus on the risks of AGI/ASI. On one hand, we have the potential to rapidly accelerate scientific advancement and solve world problems but on the other, we have an incredibly powerful unbounded intelligence that poses a potentially existential threat to humanity. We often think of AI safety in terms of “alignment” which aims to ensure the goals of a superintelligent AI and humans are aligned. A useful hypothetical to think of this is the “Paperclip Maximizer”, an AI system built to maximize the number of paperclips it can manufacture. While it has a clear and seemingly benign goal (to create paperclips), in its efforts to create paperclips it ends up destroying the Earth to derive the resources for continued paperclip generation.

Unlike many controversies, both sides of the AI safety argument are led by reputed experts in AI/ML and they fall sort of within the two camps below. I don’t think I could give their arguments justice with a short summary so I recommend just looking up their individual positions if you are interested.
We should curtail AI research for safety, the risks are too great:
We should continue AI research because the benefits outweigh the risks:
Personally, I tend to align most with the views of LeCun on AI safety who argues that:
Like any powerful technology, AI will have risks but they can be mitigated — in many cases, AI can be the solution to its own risks.
It’s inaccurately anthropomorphizing to assume they’d want to dominate humanity.
Machines will eventually surpass human intelligence in all domains and that’s OK.
The future of effects AI will be a net positive for humanity but we must work on the problem of alignment.
Overall, this feels right but I can’t confidently say we know yet what ASI will look like and just how dangerous it could be. What I do believe is that at least within the next few years, the risks involved with human uses of sub-AGI applications (whether it be AI-driven job loss, CBRN risks, cyberattacks, misinformation, neglectful AI-based decision-making, etc) are worth significant investment.