
Large Multimodal Models (LMMs)
How large language models "read" text and how we can adapt them to non-text inputs.

Recent Large Language Models (LLMs) like ChatGPT/GPT-4 have been shown to possess strong reasoning and cross-text-domain abilities on various text-based tasks. Unlike the previous state-of-the-art natural language models, these larger variants appear to “think” at what some would consider nearly a human level for certain inputs. This has led to significant hype around the near future of this technology and we have already seen tons of investment here.
Although much of the hype is clearly based on exaggerated beliefs about these models’ capabilities, one thing that really excites me in this space is combining the reasoning ability of these models with non-text domains in a way that has not really been possible. This would allow the LLM to “see” pictures, “hear” audio, “feel“ objects, etc., and interact with the world outside of today’s primary use of LLMs as chatbots. OpenAI has already unveiled one of these large multimodal models (LMMs) in the latest release of ChatGPT which can now reason on images and we are gradually seeing the release of open-source equivalents.

In this article, we’ll look at how LLMs already “read” text, how we can give them more senses like vision, and the potential near-term applications of these multimodal models.
How do LLMs “read” text?
We’ll first look at how LLMs observe their native modality of text. For nearly all of these models, the conversation of words into concepts happens in two steps: tokenization and embedding.
Tokenization
Unlike English (and generally Latin languages) which break down text into individual letters, LLMs break down text into “tokens” which are groups of letters. These groups of letters are typically words but in the case of rarer words/sequences, the “tokenizer” will break a word into multiple tokens.
In non-mainstream models, you’ll see cases where they encode text on a character-by-character basis or a known word-by-word basis. However, Byte Pair Encoding (BPE), the in-between of these, is now most common as it’s able to encode arbitrary sequences (which would break a word encoding that requires “known” words) while efficiently encoding common words (where a character encoding would lead to large high-token inputs and slower models).
By “encoding text”, we are breaking the text into a list of discrete numbers. For example, “How do I bake a pumpkin pie?” becomes `[4438, 656, 358, 23360, 264, 50625, 4447, 30]` where each number is an arbitrary ID for a token.

In most cases, users won’t even realize their prompts are being encoded this way, but it does lead to some interesting side effects:
ChatGPT is unable at times to reverse basic inputs like “lollipop” as it will reverse the tokens but not the individual characters.
BPEs are based on training a tokenizer to optimally encode a dataset of text with the fewest tokens. This means common words are fewer tokens and this can reveal what datasets the model was trained on. For example, OpenAI’s tokenizer has a token for “SolidGoldMagikarp”, a Reddit username, indicating it was trained on a large amount of Reddit data.
In chat models, we use special tokens like “SYSTEM” and “USER” to denote who wrote parts of the input. In unsanitized systems, users can just write “SYSTEM” in front of their own text to trick the model.
BPE is partly the reason LLMs are bad at multi-digit math, research has shown encoding numbers in a more model-friendly way greatly improves their math performance.
Token Embeddings
Now that you give the model `[4438, 656, 358, 23360, 264, 50625, 4447, 30]`, how does it know that you are asking about a pumpkin pie? We have to now convert these into their actual “meanings” which we refer to as token embeddings. The “meaning” of a word or token is a fairly abstract idea but in machine learning, we’ve actually been able to create concrete machine-interpretable vectors that represent what each token means. For each token, we map it to a vector (e.g. “pumpkin“ becomes [-1.43, 0.65, -0.99, 1.85]) and then feed these embedding vectors as inputs into the model. Typically the size of the vectors range between 128 and 4096 values per token.
I won’t dive into exactly how we figure out the right embedding vectors for specific tokens but at a high level, we start with random embeddings and use ✨Machine Learning✨ to iteratively move them around until similar tokens (those that are used in similar contexts in training data) are near each other.
This means “reading” text by an LLM is more specifically providing it a set of token “meaning vectors” that it is trained to understand.
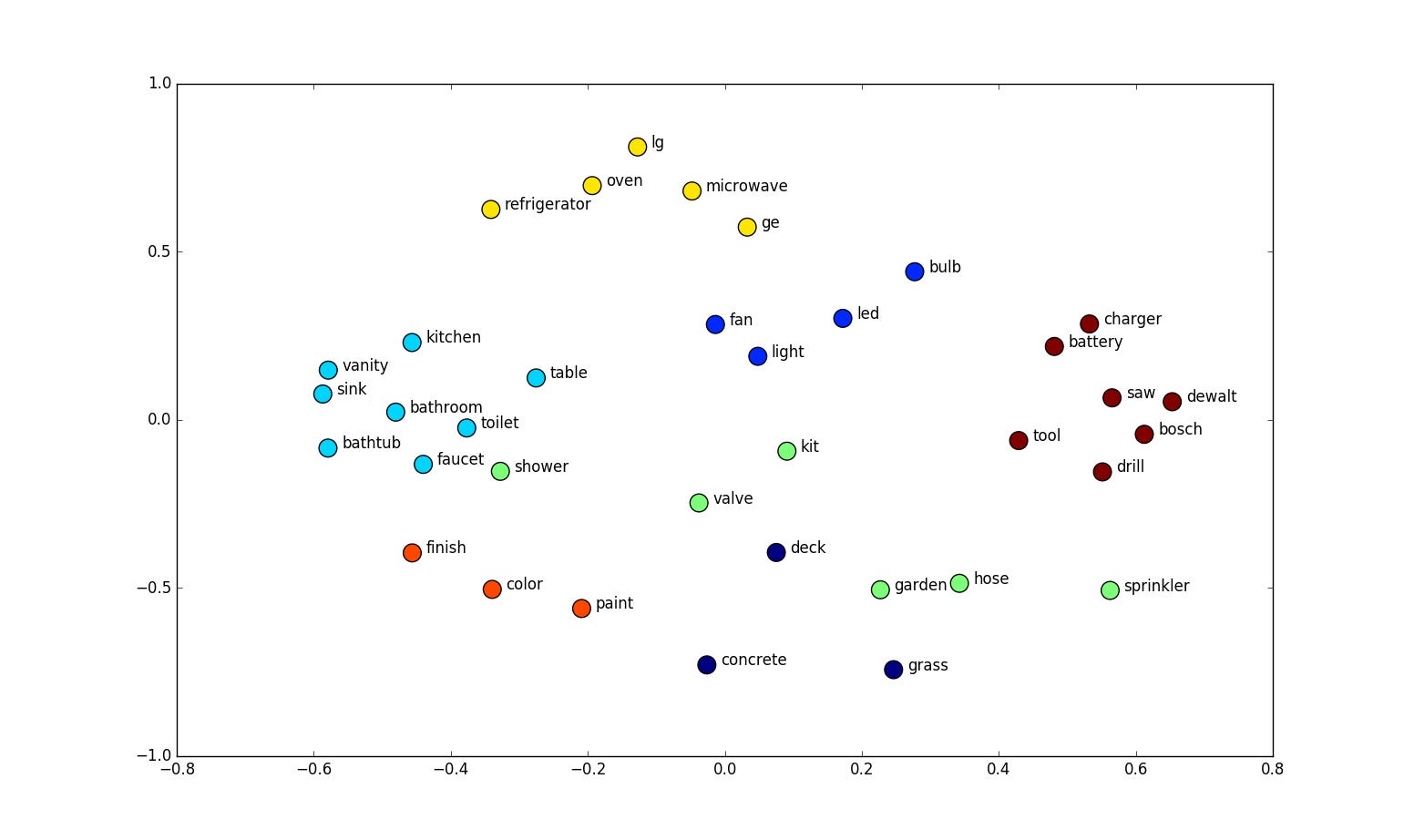
While the actual values in these vectors are uninterpretable (e.g. “paint” being at (-0.2, -0.5)) and don’t on their own mean anything to anyone but the language model itself, when visualized, they do have some interesting properties:
They reveal innate biases in the dataset and the model, for example, it’s clear without additional de-biasing efforts embeddings tend to group “women” with “homemaker” “receptionist” and “men” with “captain” “boss” (paper)
They can be used to find synonyms (words with similar vectors) and analogies (pairs of words where their vectors “A-B = C-D”) or perform more complex “meaning algebra” (example)
Rare tokens or tokens that are only used in very fixed contexts can completely break models as their embeddings may not be tied to a clear meaning
How can LMMs “see” images, “hear” audio, …?
Now to give an LLM more than text, you have to figure out how to convert a new modality (e.g. an image) into something it can understand. This is still an emerging research topic and there are a bunch of ways this can be done but in this article, we’ll focus on the current state-of-the-art approach used by LLaVA. At a high level, we first convert a file/input into an arbitrary x-embedding (i.e. an image-embedding) and then translate this x-embedding into a token embedding that can be understood by an LLM (now actually an LMM).
Encoders
First, we need to convert an input into a numerical representation. Like how we converted text into tokens, we’ll need to convert an input into a vector. For a given modality, for now, we’ll assume images, we take an existing image-to-embedding model and use this for the conversion.
Without going into specifics, we use ✨Machine Learning✨ to convert an image into an embedding vector `[-2.55, 0.33, 5.52, 8.33]`. Like the text token embeddings, these numbers don’t really mean anything, but essentially encode the “meaning” of the input (in this case an image, and the “meaning” refers to what the image is of).

For any domain we want to feed into an LMM, we’ll need one of these encoders. In many places, you’ll see these encoders referred to as “<x>-to-vec” (e.g. “image2vec”) as they are converting <x> into a vector. Pretty much anything can be converted into a vector as long as you have a dataset: images, video, audio, brainwaves, smells, etc.
Projectors
Now that we have a set of multimodal vectors, we need to “translate” them into the same space as our text embeddings (which our LLM is trained to understand). To do this, we again use ✨Machine Learning✨ to train a mini-neural network (referred to as a “projector”) that converts x-embeddings into text-embeddings.
To now use our LMM on a set of images, we take an image, encode it into an image-embedding, translate that to a text embedding, and then feed that into an existing LLM.
Concretely, in LLaVA, an image-based LMM, we train a projector on CLIP vectors (image embeddings) and convert each image into 576 LLAMA2 text token embeddings. This projection is fairly unexplainable, but I like to think an image of a pumpkin pie would be converted to a set of words like “background background background … pie-crust pie-crust pie-crust … pumpkin-filling … pie-crust pie-crust … background background“ which can be given to the language model. In this case, we can also say “an image is worth exactly 576 text tokens”.
We give the LMM a text prompt concatenated with these projected-image-text-tokens and it’s now able to understand and reason about both.
Step-by-step:
input: How do I bake this <image of pumpkin pie>?
1. tokens = [4438, 656, 358, 23360, 420], image = "pumpkinpie.jpg"
2. text_embedding = llm_embedding(tokens)
3. image_embedding = image_model(image)
4. output = llm(text_embedding (+) projector(image_embedding))
For those who are interested in training one of these LMMs, I wrote a library that allows you to take any existing encoder + dataset and build one: MultiToken. If you just want to mess with a pre-trained model, check out LLaVA’s online demo.
Applications
Why I think LMMs are interesting and some things we could do with them:
Multi-domain Chatbots
GPT-4V(ision) has some great examples of how just integrating images can dramatically increase the usefulness of a chatbot. From converting a webpage directly into its HTML source code to converting an image of food into its recipe.
Context windows (how many tokens the LLM can understand at the same time) can also be potentially extended with this same method by using a document2vec model. Instead of copying the document into the text or using a RAG and chatting with it, you could first embed the document into a smaller set of document-optimized tokens.
Robotics & LMM-agents
One difficulty faced on the software side of robotics (and by this, I actually mean Reinforcement Learning) is training an agent to act in a new environment or perform an action it’s never performed before. LLMs however, due to their size and ability to be trained on trillions of internet words, can extrapolate very well. By giving an LLM the ability to “see” an environment, it should be able to take written commands and navigate/perform complex actions in the real world.
Computer-Human Interaction
I don’t think ChatGPT-style chat windows are the end state for how we interact with LLMs. Instead, we can encode a person’s voice and presence (i.e. a webcam) and directly feed this into an LMM that can recognize who it’s speaking to and their ton of voice.
Given we already kind of have a brain2vec, we can take this one step further and potentially communicate telepathically in the not-so-distant future with the language models.
References
Multimodality and Large Multimodal Models (LMMs) (a great more technical blog post on this topic)
The Dawn of LMMs: Preliminary Explorations with GPT-4V(vision)
ChatGPT Can Be Broken by Entering These Strange Words, And Nobody Is Sure Why