
Detecting ChatGPT Online
Can you tell if text is generated by ChatGPT?

The recent rise of large language models (LLMs) and ChatGPT has worried many as the models become ever more accessible and approach a level of being nearly indistinguishable from human-written text. The risks of not being able to differentiate AI-generated and human text include the general “poisoning of the internet”, mass academic plagiarism, and augmented mass disinformation campaigns.
In this article, we look at the current methods used for ChatGPT detection and how well they work on a toy dataset.
The Experiment
We’ll use Kaggle’s Movie Reviews 2015 dataset as a baseline for human-generated text, generate several ChatGPT reviews with the OpenAI API, and then analyze the results.
To generate the ChatGPT review, we use gpt-3.5-turbo at a high temperature with the prompt:
Write a {k}-word movie review for a random movie (do not include the movie name). Start it with '{two_words}'.
Where {k} and {two_words} are taken from real data to seed unique examples. If you did “write a review”, nearly all the examples would be identical even with a high temperature (I tried it).
To get a sense of the data here’s a human and ChatGPT review:
To the filmmakers, Ivan is a prince of a fellow, but he comes across as shallow and glib though not mean-spirited, and there's no indication that he's been responsible for putting together any movies of particular value or merit. - Human
To the unpredictable and captivating film that takes us on an emotional rollercoaster. Brilliant performances, stunning visuals, and a gripping storyline make this a must-watch. A true masterpiece that will leave you in awe. - ChatGPT
Method 1: Human
Many people believe they can spot the difference and studies on specific domains of text show that humans are much better than random chance at distinguishing them. Often people base it on the text being too generic, too perfect, or while seemingly correct it contains an obvious logical error.
To test my ability on these reviews, I gave myself 100 examples (50 real, 50 ChatGPT) and labeled them.
Going through these, what seemed to be indicative of ChatGPT were very generic reviews (nothing specific about the movie), neutral tones, and how often “emotional rollercoaster” came up. Human reviews also tended to mention external information like the theater experience or details from someone on the cast.

Now looking at the results, I did far worse than I thought I was doing while taking the test. I was somewhat able to classify real texts correctly but completely 50/50 for texts that were actually ChatGPT.
Takeaways: Humans can in some cases tell if text is ChatGPT generated but tend to often overestimate their own abilities on this task.
Method 2: Text Statistics
Another method is to use the frequency of words or more advanced text metrics to determine if it’s real or ChatGPT.

Here we see minor differences between common words in both texts, ChatGPT tended to use “a” and “this” more frequently while humans tended to use more “in” and “of”. This isn’t that useful for checking individual examples but if you had a set of texts (e.g. for a specific suspected bot user) these types of frequencies could be useful.

We also see clear differentiation using a set of various readability scores, especially with Linsear Write. These scores measure the “difficulty” of the text and as one might suspect ChatGPT uses “easy words” by default and this gives it away. It’s totally possible to ask ChatGPT to write using more sophisticated words and this could easily confound this approach.
This could also be extended by encoding these word frequencies and scores and training a light model to classify them, however, it’s likely to overfit to the specific synthetic prompt and have issues detecting ChatGPT text in the wild.
Some have also trained large text models to perform this task without score-specific feature engineering like roberta-base-openai-detector however in practice these larger models have similar limitations.

Takeaways: Text statistics can be a reliable and fast way to differentiate generic ChatGPT and human text. As adversaries begin to use a more diverse set of models and writing styles, our ability to detect them using this method will dissipate.
Method 4: Perplexity
Perplexity is a metric for how well a model predicts the words in a piece of text. ChatGPT and LLMs in general work by predicting the next words over and over and we traditionally measure how good they are at that via perplexity. As a potential example of Goodhart's law, this makes ChatGPT in some sense over-optimize perplexity by choosing words that are very statistically likely given the previous ones in a way that’s too perfect for a human to replicate. An interesting side effect of this method on online GPT detectors is that common texts or phrases (like the U.S. Constitution shown below) have an extremely low perplexity and they might seem AI-generated to these systems.
We the People of the United States, in Order to form a more perfect Union, establish Justice, insure domestic Tranquility, provide for the common defense, promote the general Welfare, and secure the Blessings of Liberty to ourselves and our Posterity, do ordain and establish this Constitution for the United States of America.
GPT2 Perplexity = 3 (very likely text, low perplexity)
asdj asdk ;als das d;jasd jasdi haisldh ao;isdy ;augsdagud gsadasd ha siuodaysd ;
GPT2 Perplexity = 746 (completely random keyboard mash, high perplexity)
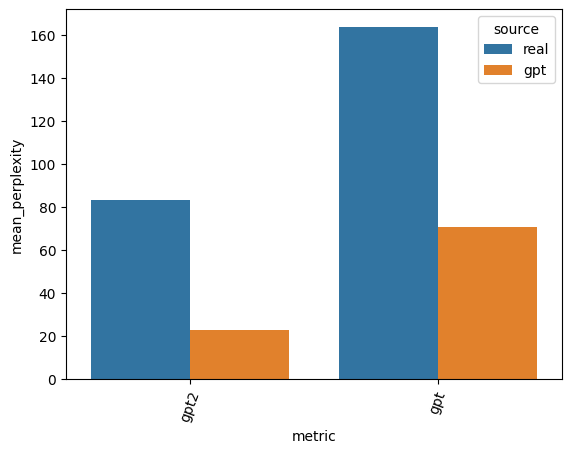
The perplexity score is model-specific and for the best results, you’d want the same model the potentially synthetic content was created with. Here I use GPT (original) and GPT2 as open-source proxies to ChatGPT. We can see that real human texts have much higher average perplexity distinguishing them from low-perplexity AI-generated text.
Takeaways: Perplexity uses the model’s own training against it. It can work for any generic AI-generated text given you have a reasonable proxy for the generative model. However, it starts to fail for more complex prompts and can be expensive given it requires running the full LLM.
Method 5: Top-K Alignment
A similar but potentially more intuitive measure is to compute the alignment between what the LLM would have predicted and the actual words in the text. We run the LLM alongside the text for each word and then compare the LLM’s top 5 next potential words to the actual word in the text. If the text often matches the LLM’s top predictions, then it’s potentially AI-generated.
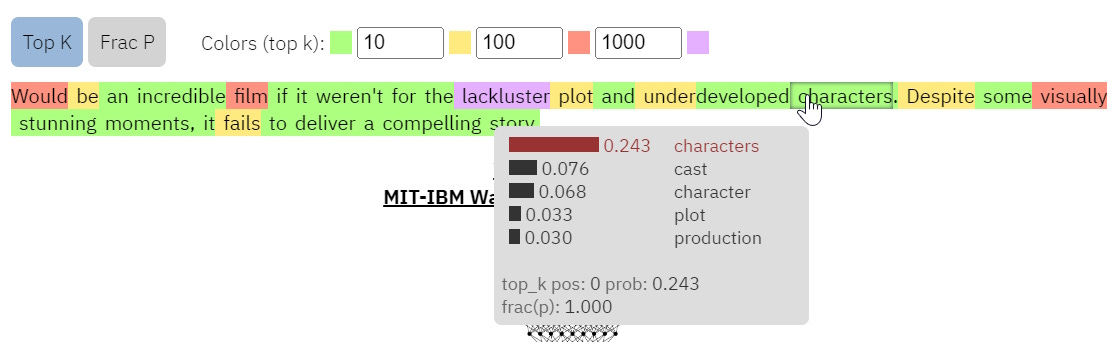
Like perplexity, you want to have a reference model that’s nearly identical to the one used to generate the AI text. It also means this method can get very expensive as you have to run the entire LLM to check whether a piece of text is AI-generated.

We see that for every value of K, ChatGPT reviews more often align with what GPT2 would have predicted. As you increase the value of K, the percentage of aligned tokens increases and it’s harder to tell them apart.
Takeaways: Top-K is a more intuitive and explainable metric to perplexity with the same limitations.
Method 6: Asking ChatGPT
To me, one of the least intuitive methods is to just ask ChatGPT itself if a text is AI-generated. Even if this was a capability of internet-trained LLMs, the LLM would not have been able to see its own outputs in the training dataset (maybe through RLHF?). Studies have shown that this method isn’t great for classifying synthetic text but it can reasonably confirm if human-generated content is generated by a human and that it takes a lot of prompting effort to get it to work.
I used the following prompt on 100 examples (50 real, 50 fake):
Is the following text generated with ChatGPT (this is from a 50/50 dataset), respond yes or no. '{review}'

ChatGPT can confidently say a human text is human but struggles with classifying its own text correctly. I also ran this with GPT4 and the resulting accuracy on the same prompt and dataset was 49%.
Takeaways: ChatGPT in some sense does know what isn’t its own default voice. This seems to be potentially the most expensive and one of the least effective detection methods, although purely from accuracy, it did do better than me for these movie reviews.
Method 7: Watermarking
One method that’s still being developed is to apply non-human detectable watermarks to the generated text. Similar to steganography, these techniques hide a signature within the text by slightly modifying words in a way that doesn’t modify the original meaning. These methods are designed so that are robust to basic common changes (pulling out substrings, tweaking words, etc.).
While longer term this may be one of the only methods that works for AI generation detection, it relies on being in control of the decoder. Those who have access to open-source models can generate text without the watermark or fine-tune it out of the model.
Takeaways: As generative AI actors find more sophisticated techniques to obfuscate the style and prompts of texts, watermarking might be the only long-term defense. However, powerful open-source models make it only a partial solution.
Limitations
This experiment was a toy study to demonstrate various techniques for differentiating human and ChatGPT text. Here are some of the key limitations to note:
This was a very small dataset (n=100 real, n=100 fake)
The results are heavily dependent on the context of the generated text, the length, and the prompts
It’s likely that as the models behind ChatGPT get larger and trained novel datasets, open-source proxies like GPT2 will perform worse
Having different mean values between sources != reliably able to differentiate individual examples as AI or not AI. Potentially featurizing these scores and training a classification model could give you decent results but you’ll like overfit to the prompt used to generate the synthetic examples.
These techniques also tend to bias against:
Text written by non-native English speakers
Text whose content contains common phrases, quotations, or repetitive words
Online Detectors
It’s likely many, if not most, online GPT detectors are using some variant or combination of the techniques listed above. However, if they can do it (and we can do it in this article) why did OpenAI themselves take down their GPT text detector due to it’s low accuracy? I think this comes down to:
Classifying a single example on its own is much harder than classifying a corpora of text (i.e. it is reasonable to classify a Reddit account’s comment history as ChatGPT spam but not a single comment on its own).
“Accuracy” can be a very misleading and almost useless term for any universal online detector as it depends on the underlying distribution. If gptzero measures their accuracy on a dataset on mixed internet content and you as a teacher use it for essay plagiarism — the effective accuracies, precision, and recall will not be the same.
The more text, the more information that can be used to differentiate. Many of these detectors break down on short texts.
The results of generic prompts (e.g. “Write me an essay”) are easier to detect than complex ones (e.g. “Read this text, write an essay in the style of…”) as the former will tend to take on the same tone and word choice.
References
Will ChatGPT get you caught? Rethinking of Plagiarism Detection
Fighting Fire with Fire: Can ChatGPT Detect AI-generated Text?
Real or Fake Text?: Investigating Human Ability to Detect Boundaries
Catching a Unicorn with GLTR: A tool to detect automatically generated text
Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding